 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyadic Speech-based Affect Recognition using DAMI-P2C Parent-child Multimodal Interaction Dataset
Paper and Code
Aug 20, 2020
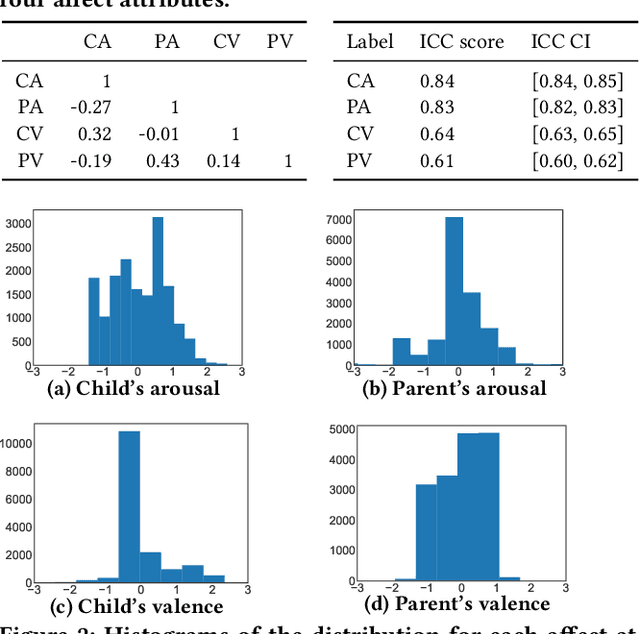

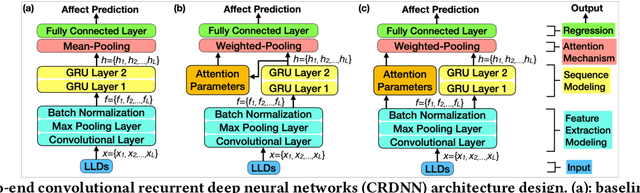
Automatic speech-based affect recognition of individuals in dyadic conversation is a challenging task, in part because of its heavy reliance on manual pre-processing. Traditional approaches frequently require hand-crafted speech features and segmentation of speaker turns. In this work, we design end-to-end deep learning methods to recognize each person's affective expression in an audio stream with two speakers, automatically discovering features and time regions relevant to the target speaker's affect. We integrate a local attention mechanism into the end-to-end architecture and compare the performance of three attention implementations -- one mean pooling and two weighted pooling methods. Our results show that the proposed weighted-pooling attention solutions are able to learn to focus on the regions containing target speaker's affective information and successfully extract the individual's valence and arousal intensity. Here we introduce and use a "dyadic affect in multimodal interaction - parent to child" (DAMI-P2C) dataset collected in a study of 34 families, where a parent and a child (3-7 years old) engage in reading storybooks together. In contrast to existing public datasets for affect recognition, each instance for both speakers in the DAMI-P2C dataset is annotated for the perceived affect by three labelers. To encourage more research on the challenging task of multi-speaker affect sensing, we make the annotated DAMI-P2C dataset publicly available, including acoustic features of the dyads' raw audios, affect annotations, and a diverse set of developmental, social, and demographic profiles of each dyad.