 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Adversarial Attacks without Adversarial Attacks in Deep Reinforcement Learning
Paper and Code

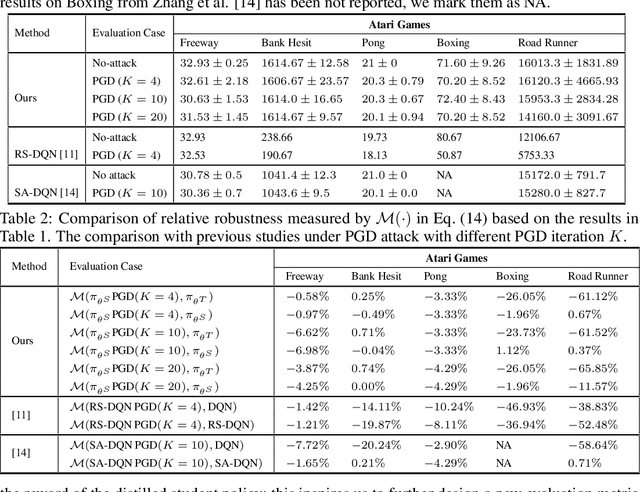

Many recent studies in deep reinforcement learning (DRL) have proposed to boost adversarial robustness through policy distillation utilizing adversarial training, where additional adversarial examples are added in the training process of the student policy; this makes the robustness improvement less flexible and more computationally expensive. In contrast, we propose an efficient policy distillation paradigm called robust policy distillation that is capable of achieving an adversarially robust student policy without relying on any adversarial example during student policy training. To this end, we devise a new policy distillation loss that consists of two terms: 1) a prescription gap maximization loss aiming at simultaneously maximizing the likelihood of the action selected by the teacher policy and the entropy over the remaining actions; 2) a Jacobian regularization loss that minimizes the magnitude of Jacobian with respect to the input state. The theoretical analysis proves that our distillation loss guarantees to increase the prescription gap and the adversarial robustness. Meanwhile, experiments on five Atari games firmly verifies the superiority of our policy distillation on boosting adversarial robustness compared to other state-of-the-arts.