 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Paper and Code
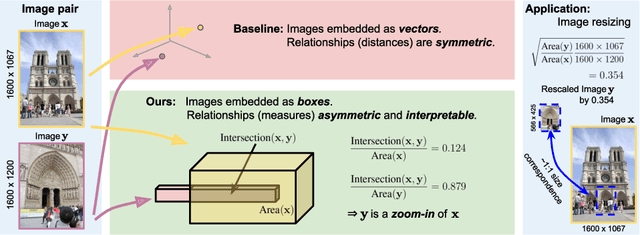
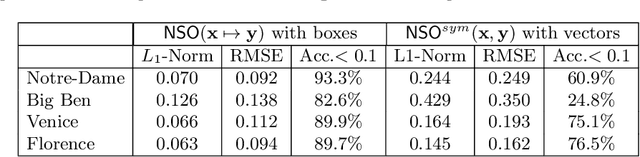

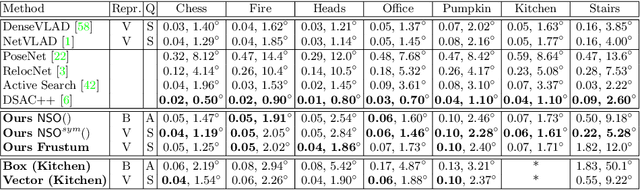
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.