Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Motion Estimation via Motion Compression and Refinement
Paper and Code

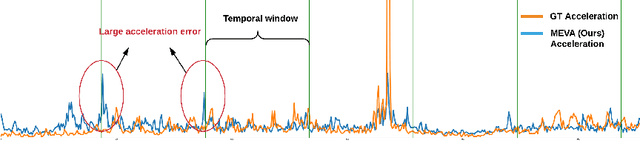
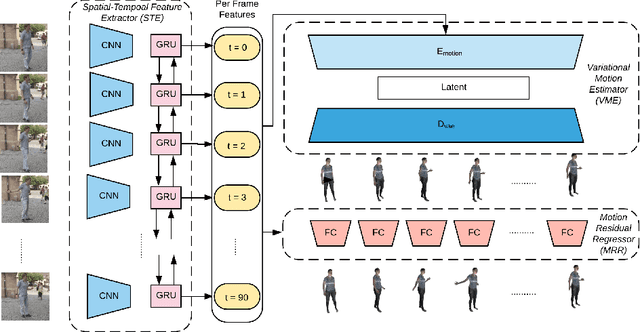
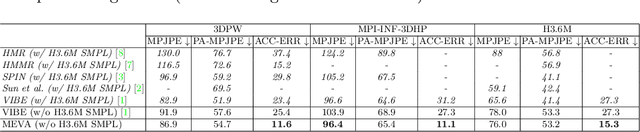
We develop a technique for generating smooth and accurate 3D human pose and motion estimates from RGB video sequences. Our technique, which we call Motion Estimation via Variational Autoencoder (MEVA), decomposes a temporal sequence of human motion into a smooth motion representation using auto-encoder-based motion compression and a residual representation learned through motion refinement. This two-step encoding of human motion captures human motion in two stages: a general human motions estimation step that captures the coarse overall motion, and a residual estimation that adds back person-specific motion details. Experiments show that our method produces both smooth and accurate 3D human pose and motion estimates.
View paper on