 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR Data Enrichment Using Deep Learning Based on High-Resolution Image: An Approach to Achieve High-Performance LiDAR SLAM Using Low-cost LiDAR
Paper and Code
Aug 09, 2020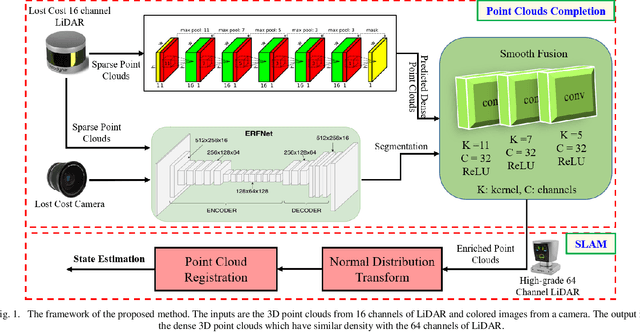


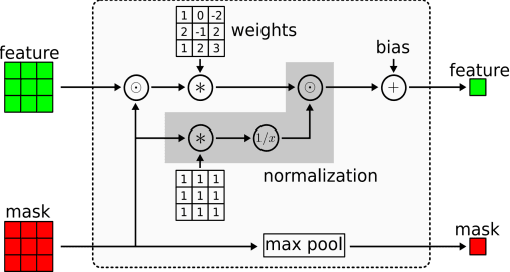
LiDAR-based SLAM algorithms are extensively studied to providing robust and accurate positioning for autonomous driving vehicles (ADV) in the past decades. Satisfactory performance can be obtained using high-grade 3D LiDAR with 64 channels, which can provide dense point clouds. Unfortunately, the high price significantly prevents its extensive commercialization in ADV. The cost-effective 3D LiDAR with 16 channels is a promising replacement. However, only limited and sparse point clouds can be provided by the 16 channels LiDAR, which cannot guarantee sufficient positioning accuracy for ADV in challenging dynamic environments. The high-resolution image from the low-cost camera can provide ample information about the surroundings. However, the explicit depth information is not available from the image. Inspired by the complementariness of 3D LiDAR and camera, this paper proposes to make use of the high-resolution images from a camera to enrich the raw 3D point clouds from the low-cost 16 channels LiDAR based on a state-of-the-art deep learning algorithm. An ERFNet is firstly employed to segment the image with the aid of the raw sparse 3D point clouds. Meanwhile, the sparse convolutional neural network is employed to predict the dense point clouds based on raw sparse 3D point clouds. Then, the predicted dense point clouds are fused with the segmentation outputs from ERFnet using a novel multi-layer convolutional neural network to refine the predicted 3D point clouds. Finally, the enriched point clouds are employed to perform LiDAR SLAM based on the state-of-the-art normal distribution transform (NDT). We tested our approach on the re-edited KITTI datasets: (1)the sparse 3D point clouds are significantly enriched with a mean square error of 1.1m MSE. (2)the map generated from the LiDAR SLAM is denser which includes more details without significant accuracy loss.