 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Frames with Efficient Pseudo-3D CNN for Human Action Recognition
Paper and Code
Aug 03, 2020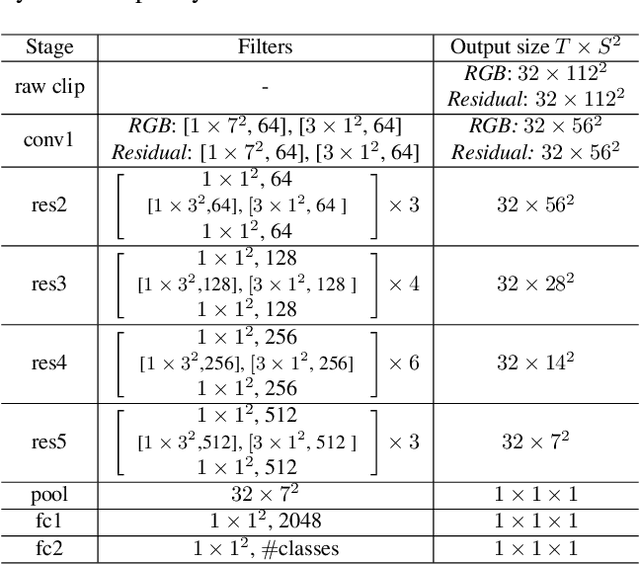
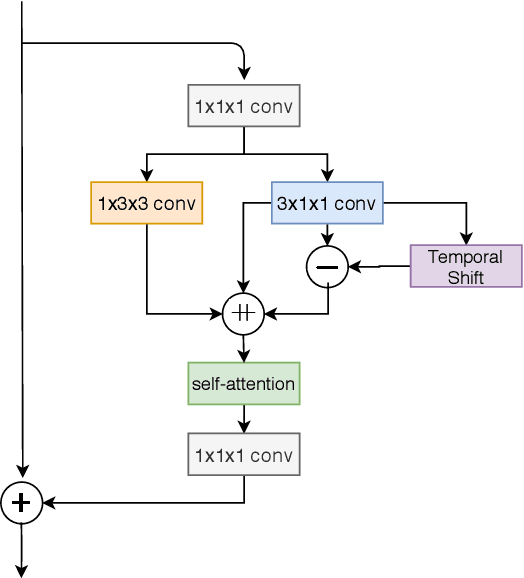
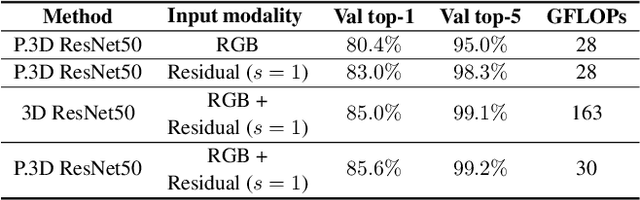

Human action recognition is regarded as a key cornerstone in domains such as surveillance or video understanding. Despite recent progress in the development of end-to-end solutions for video-based action recognition, achieving state-of-the-art performance still requires using auxiliary hand-crafted motion representations, e.g., optical flow, which are usually computationally demanding. In this work, we propose to use residual frames (i.e., differences between adjacent RGB frames) as an alternative "lightweight" motion representation, which carries salient motion information and is computationally efficient. In addition, we develop a new pseudo-3D convolution module which decouples 3D convolution into 2D and 1D convolution. The proposed module exploits residual information in the feature space to better structure motions, and is equipped with a self-attention mechanism that assists to recalibrate the appearance and motion features. Empirical results confirm the efficiency and effectiveness of residual frames as well as the proposed pseudo-3D convolution module.