 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-node Bert-pretraining: Cost-efficient Approach
Paper and Code
Aug 01, 2020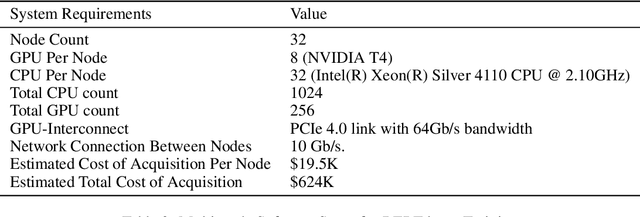
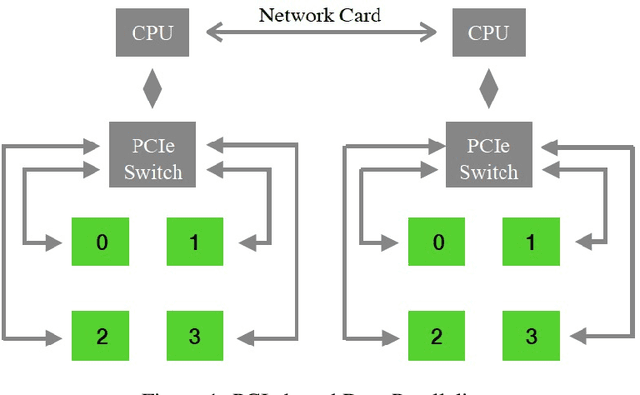
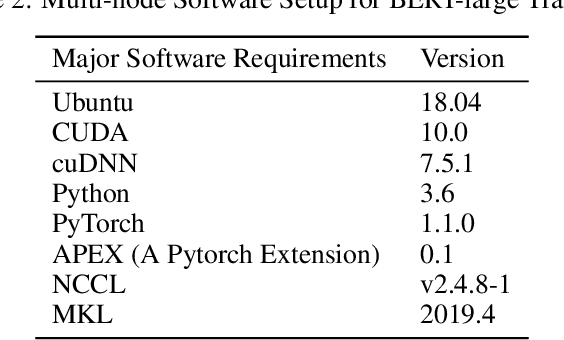

Recently, large scale Transformer-based language models such as BERT, GPT-2, and XLNet have brought about exciting leaps in state-of-the-art results for many Natural Language Processing (NLP) tasks. One of the common trends in these recent models is a significant increase in model complexity, which introduces both more weights and computation. Moreover, with the advent of large-scale unsupervised datasets, training time is further extended due to the increased amount of data samples within a single training epoch. As a result, to train these models within a reasonable time, machine learning (ML) programmers often require advanced hardware setups such as the premium GPU-enabled NVIDIA DGX workstations or specialized accelerators such as Google's TPU Pods. Our work addresses this limitation and demonstrates that the BERT pre-trained model can be trained within 2 weeks on an academic-size cluster of widely available GPUs through careful algorithmic and software optimizations. In this paper, we present these optimizations on how to improve single device training throughput, distribute the training workload over multiple nodes and GPUs, and overcome the communication bottleneck introduced by the large data exchanges over the network. We show that we are able to perform pre-training on BERT within a reasonable time budget (12 days) in an academic setting, but with a much less expensive and less aggressive hardware resource requirement than in previously demonstrated industrial settings based on NVIDIA DGX machines or Google's TPU Pods.