 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-and-Action Aware Model for Visual Language Navigation
Paper and Code
Jul 29, 2020
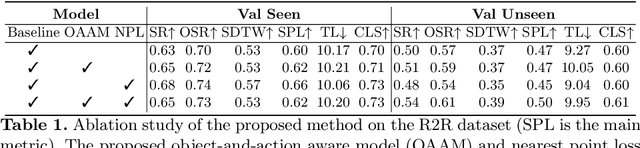
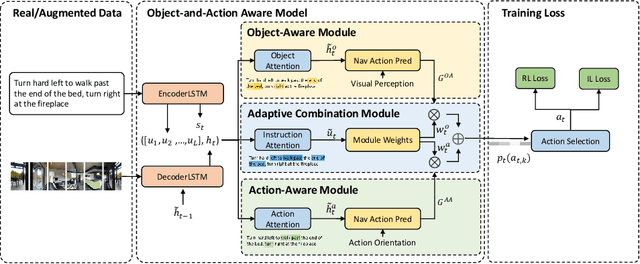
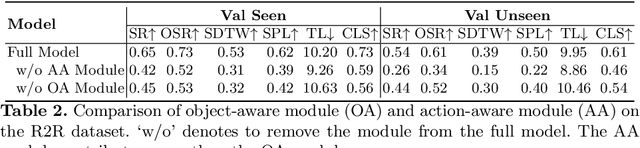
Vision-and-Language Navigation (VLN) is unique in that it requires turning relatively general natural-language instructions into robot agent actions, on the basis of the visible environment. This requires to extract value from two very different types of natural-language information. The first is object description (e.g., 'table', 'door'), each presenting as a tip for the agent to determine the next action by finding the item visible in the environment, and the second is action specification (e.g., 'go straight', 'turn left') which allows the robot to directly predict the next movements without relying on visual perceptions. However, most existing methods pay few attention to distinguish these information from each other during instruction encoding and mix together the matching between textual object/action encoding and visual perception/orientation features of candidate viewpoints. In this paper, we propose an Object-and-Action Aware Model (OAAM) that processes these two different forms of natural language based instruction separately. This enables each process to match object-centered/action-centered instruction to their own counterpart visual perception/action orientation flexibly. However, one side-issue caused by above solution is that an object mentioned in instructions may be observed in the direction of two or more candidate viewpoints, thus the OAAM may not predict the viewpoint on the shortest path as the next action. To handle this problem, we design a simple but effective path loss to penalize trajectories deviating from the ground truth path. Experimental results demonstrate the effectiveness of the proposed model and path loss, and the superiority of their combination with a 50% SPL score on the R2R dataset and a 40% CLS score on the R4R dataset in unseen environments, outperforming the previous state-of-the-art.