 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-expression spotting: A new benchmark
Paper and Code
Jul 24, 2020
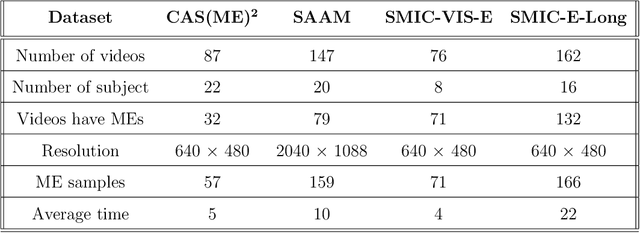

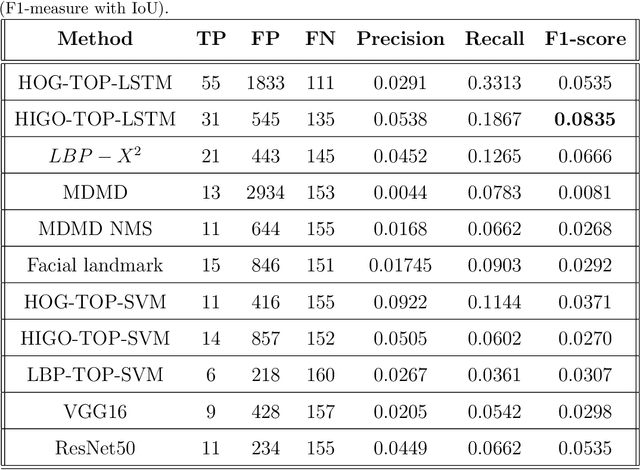
Micro-expressions (MEs) are brief and involuntary facial expressions that occur when people are trying to hide their true feelings or conceal their emotions. Based on psychology research, MEs play an important role in understanding genuine emotions, which leads to many potential applications. Therefore, ME analysis has been becoming an attractive topic for various research areas, such as psychology, law enforcement, and psychotherapy. In the computer vision field, the study of MEs can be divided into two main tasks: spotting and recognition, which are to identify positions of MEs in videos and determine the emotion category of detected MEs, respectively. Recently, although much research has been done, the construction of a fully automatic system for analyzing MEs is still far away from practice. This is because of two main reasons: most of the research in MEs only focuses on the recognition part while abandons the spotting task; current public datasets for ME spotting are not challenging enough to support developing a robust spotting algorithm. Our contributions in this paper are three folds: (1) We introduce an extension of the SMIC-E database, namely SMIC-E-Long database, which is a new challenging benchmark for ME spotting. (2) We suggest a new evaluation protocol that standardizes the comparison of various ME spotting techniques. (3) Extensive experiments with handcrafted and deep learning-based approaches on the SMIC-E-Long database are performed for baseline evaluation.