 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePClean: Bayesian Data Cleaning at Scale with Domain-Specific Probabilistic Programming
Paper and Code

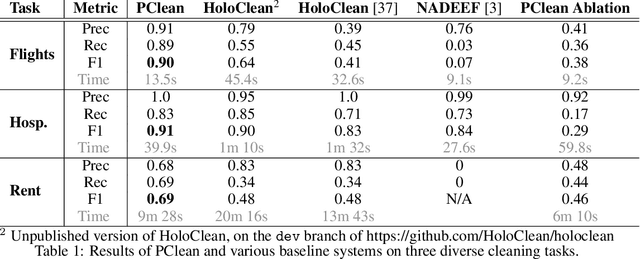

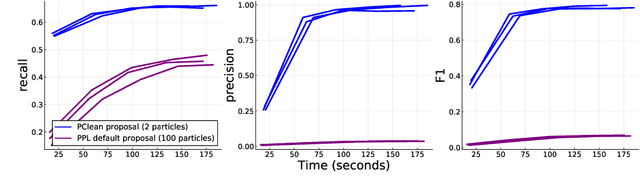
Data cleaning is naturally framed as probabilistic inference in a generative model, combining a prior distribution over ground-truth databases with a likelihood that models the noisy channel by which the data are filtered, corrupted, and joined to yield incomplete, dirty, and denormalized datasets. Based on this view, we present PClean, a unified generative modeling architecture for cleaning and normalizing dirty data in diverse domains. Given an unclean dataset and a probabilistic program encoding relevant domain knowledge, PClean learns a structured representation of the data as a relational database of interrelated objects, and uses this latent structure to impute missing values, identify duplicates, detect errors, and propose corrections in the original data table. PClean makes three modeling and inference contributions: (i) a domain-general non-parametric generative model of relational data, for inferring latent objects and their network of latent connections; (ii) a domain-specific probabilistic programming language, for encoding domain knowledge specific to each dataset being cleaned; and (iii) a domain-general inference engine that adapts to each PClean program by constructing data-driven proposals used in sequential Monte Carlo and particle Gibbs. We show empirically that short (< 50-line) PClean programs deliver higher accuracy than state-of-the-art data cleaning systems based on machine learning and weighted logic; that PClean's inference algorithm is faster than generic particle Gibbs inference for probabilistic programs; and that PClean scales to large real-world datasets with millions of rows.