 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Prioritized Replay: Sampling States in Model-Based RL via Simulated Priorities
Paper and Code
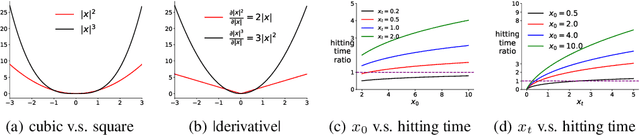

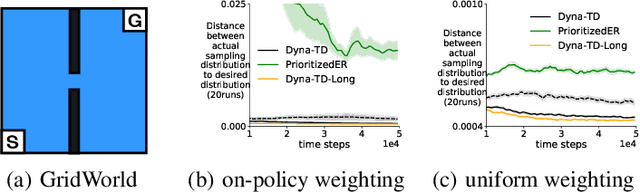
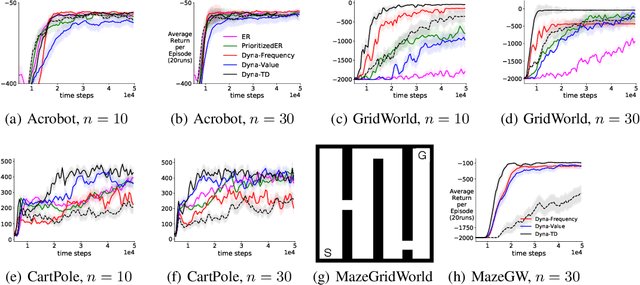
Model-based reinforcement learning (MBRL) can significantly improve sample efficiency, particularly when carefully choosing the states from which to sample hypothetical transitions. Such prioritization has been empirically shown to be useful for both experience replay (ER) and Dyna-style planning. However, there is as yet little theoretical understanding in RL about such prioritization strategies, and why they help. In this work, we revisit prioritized ER and, in an ideal setting, show an equivalence to minimizing cubic loss, providing theoretical insight into why it improves upon uniform sampling. This ideal setting, however, cannot be realized in practice, due to insufficient coverage of the sample space and outdated priorities of training samples. This motivates our model-based approach, which does not suffer from these limitations. Our key idea is to actively search for high priority states using gradient ascent. Under certain conditions, we prove that the distribution of hypothetical experiences generated from these states provides a diverse set of states, sampled proportionally to approximately true priorities. Our experiments on both benchmark and application-oriented domain show that our approach achieves superior performance over both the model-free prioritized ER method and several closely related model-based baselines.