 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Non-Autoregressive Model for Human Motion Prediction
Paper and Code
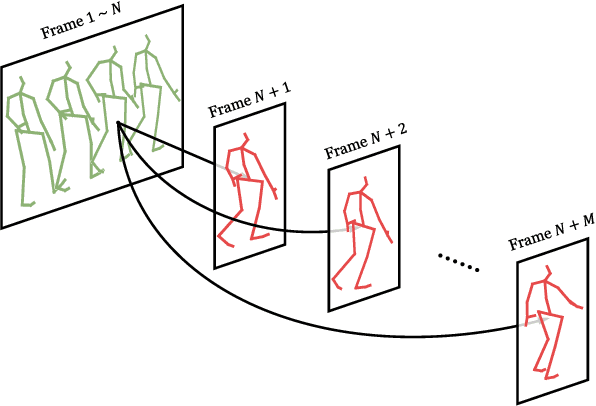
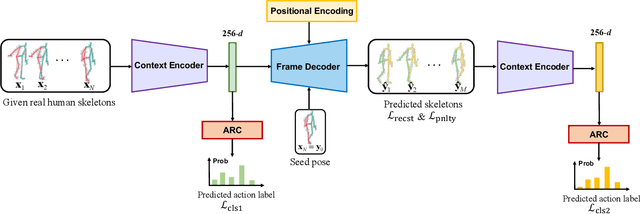
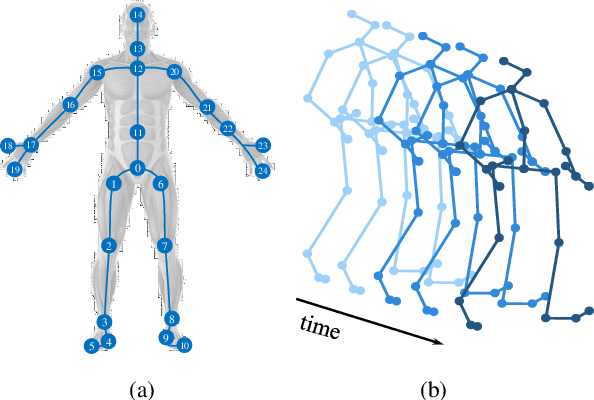
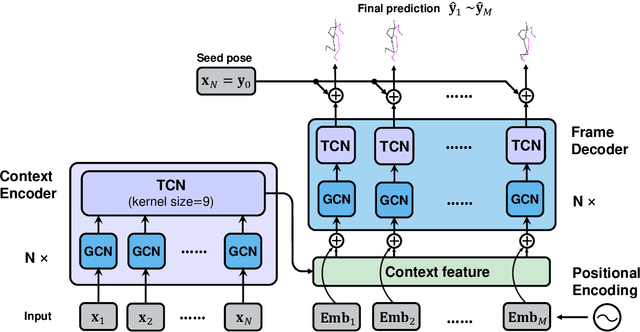
Human motion prediction, which aims at predicting future human skeletons given the past ones, is a typical sequence-to-sequence problem. Therefore, extensive efforts have been continued on exploring different RNN-based encoder-decoder architectures. However, by generating target poses conditioned on the previously generated ones, these models are prone to bringing issues such as error accumulation problem. In this paper, we argue that such issue is mainly caused by adopting autoregressive manner. Hence, a novel Non-auToregressive Model (NAT) is proposed with a complete non-autoregressive decoding scheme, as well as a context encoder and a positional encoding module. More specifically, the context encoder embeds the given poses from temporal and spatial perspectives. The frame decoder is responsible for predicting each future pose independently. The positional encoding module injects positional signal into the model to indicate temporal order. Moreover, a multitask training paradigm is presented for both low-level human skeleton prediction and high-level human action recognition, resulting in the convincing improvement for the prediction task. Our approach is evaluated on Human3.6M and CMU-Mocap benchmarks and outperforms state-of-the-art autoregressive methods.