 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning on the fast lane: Learning to interact using attention mechanisms in path integral inverse reinforcement learning
Paper and Code
Jul 11, 2020
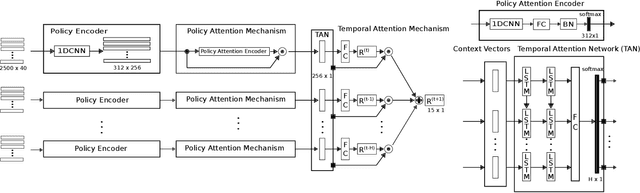
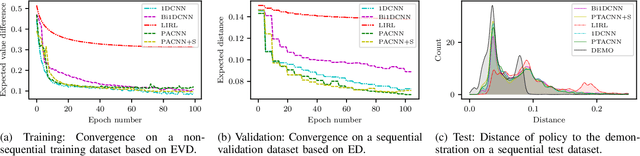
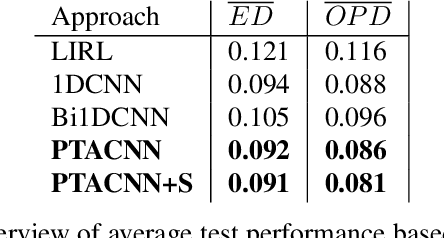
General-purpose trajectory planning algorithms for automated driving utilize complex reward functions to perform a combined optimization of strategic, behavioral, and kinematic features. The specification and tuning of a single reward function is a tedious task and does not generalize over a large set of traffic situations. Deep learning approaches based on path integral inverse reinforcement learning have been successfully applied to predict local situation-dependent reward functions using features of a set of sampled driving policies. Sample-based trajectory planning algorithms are able to approximate a spatio-temporal subspace of feasible driving policies that can be used to encode the context of a situation. However, the interaction with dynamic objects requires an extended planning horizon, which requires sequential context modeling. In this work, we are concerned with the sequential reward prediction over an extended time horizon. We present a neural network architecture that uses a policy attention mechanism to generate a low-dimensional context vector by concentrating on trajectories with a human-like driving style. Besides, we propose a temporal attention mechanism to identify context switches and allow for stable adaptation of rewards. We evaluate our results on complex simulated driving situations, including other vehicles. Our evaluation shows that our policy attention mechanisms learns to focus on collision free policies in the configuration space. Furthermore, the temporal attention mechanism learns persistent interaction with other vehicles over an extended planning horizon.