 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDprop: Does Jacobi Preconditioning Help Temporal Difference Learning?
Paper and Code
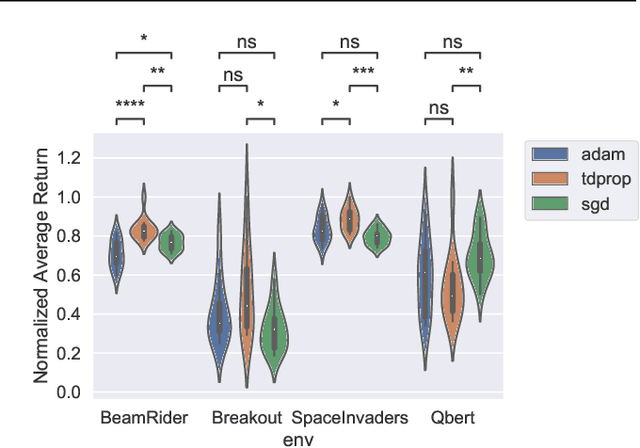

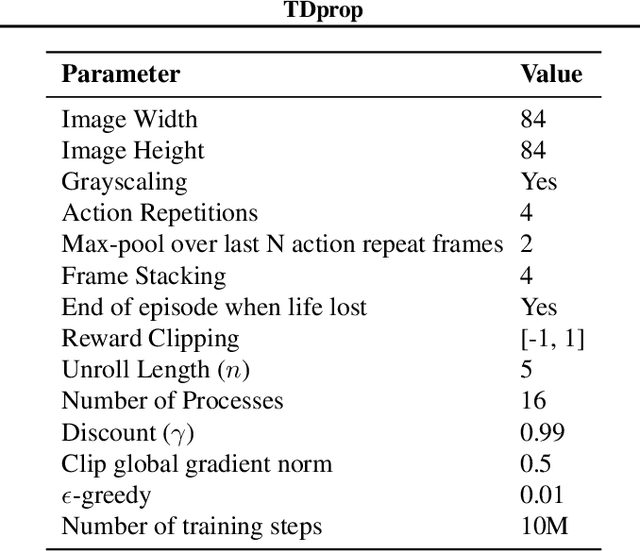
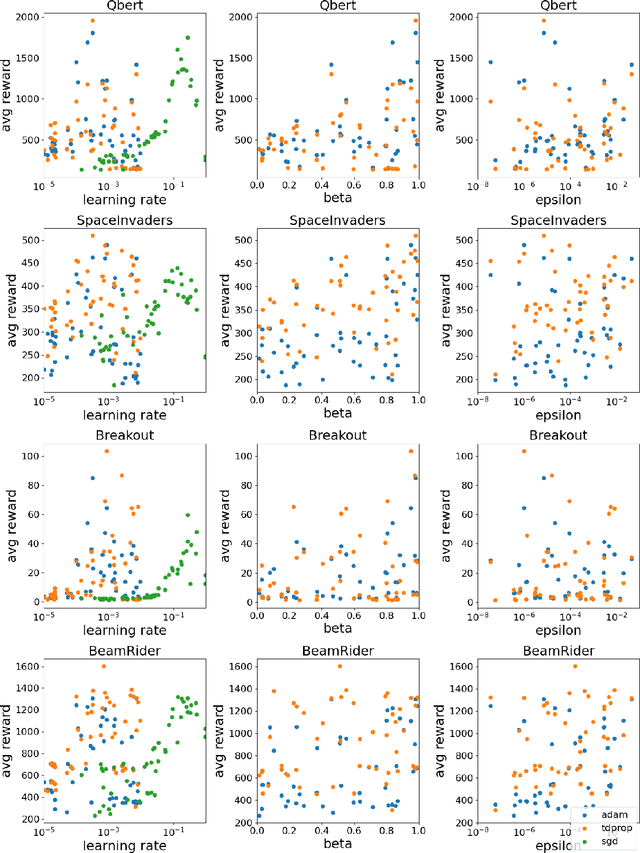
We investigate whether Jacobi preconditioning, accounting for the bootstrap term in temporal difference (TD) learning, can help boost performance of adaptive optimizers. Our method, TDprop, computes a per parameter learning rate based on the diagonal preconditioning of the TD update rule. We show how this can be used in both $n$-step returns and TD($\lambda$). Our theoretical findings demonstrate that including this additional preconditioning information is, surprisingly, comparable to normal semi-gradient TD if the optimal learning rate is found for both via a hyperparameter search. In Deep RL experiments using Expected SARSA, TDprop meets or exceeds the performance of Adam in all tested games under near-optimal learning rates, but a well-tuned SGD can yield similar improvements -- matching our theory. Our findings suggest that Jacobi preconditioning may improve upon typical adaptive optimization methods in Deep RL, but despite incorporating additional information from the TD bootstrap term, may not always be better than SGD.