 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Handwritten Chinese Text Recognition with Convolutional Neural Networks
Paper and Code
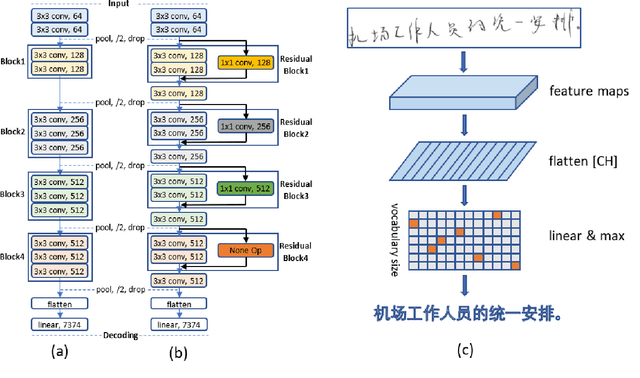
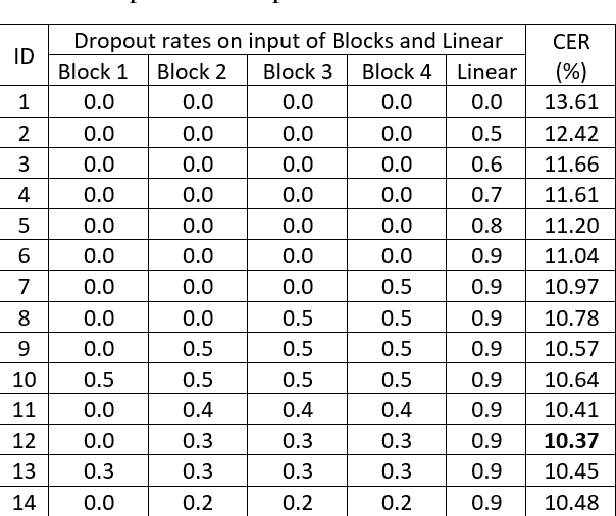
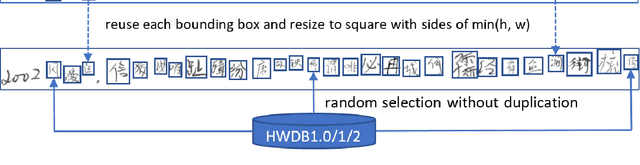
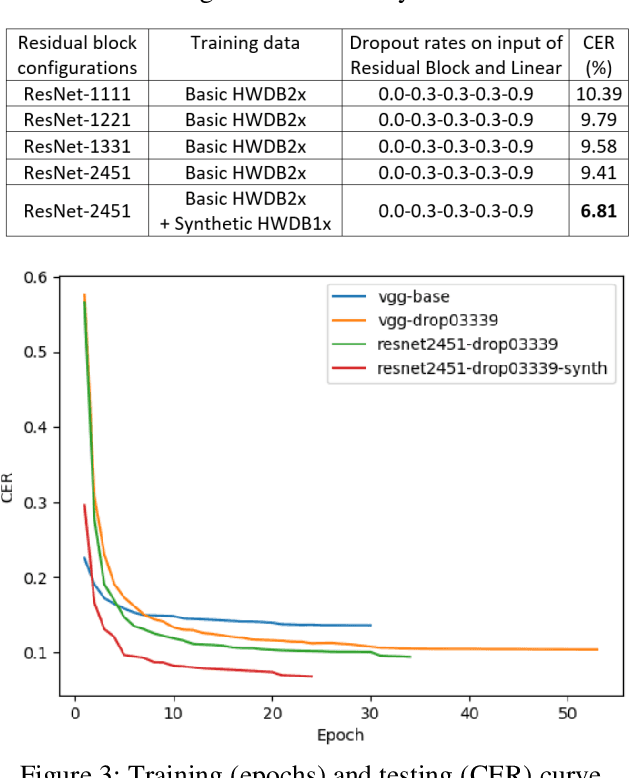
Deep learning based methods have been dominating the text recognition tasks in different and multilingual scenarios. The offline handwritten Chinese text recognition (HCTR) is one of the most challenging tasks because it involves thousands of characters, variant writing styles and complex data collection process. Recently, the recurrent-free architectures for text recognition appears to be competitive as its highly parallelism and comparable results. In this paper, we build the models using only the convolutional neural networks and use CTC as the loss function. To reduce the overfitting, we apply dropout after each max-pooling layer and with extreme high rate on the last one before the linear layer. The CASIA-HWDB database is selected to tune and evaluate the proposed models. With the existing text samples as templates, we randomly choose isolated character samples to synthesis more text samples for training. We finally achieve 6.81% character error rate (CER) on the ICDAR 2013 competition set, which is the best published result without language model correction.