Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Predictability of Pruning Across Scales
Paper and Code
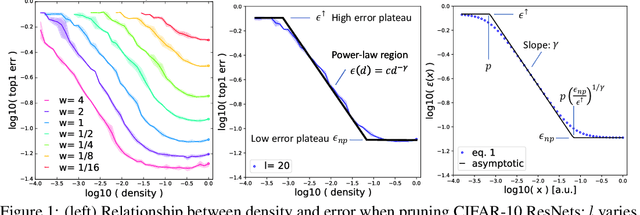
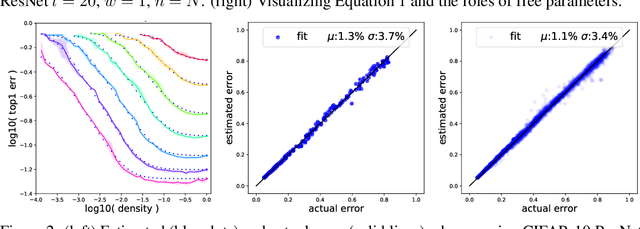
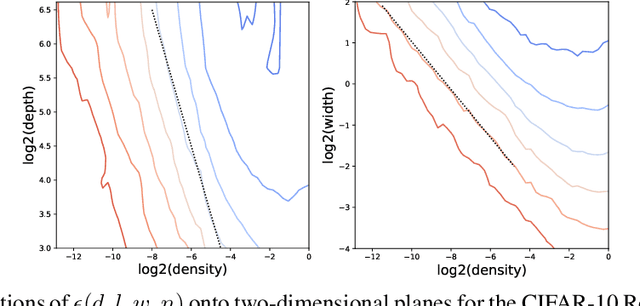
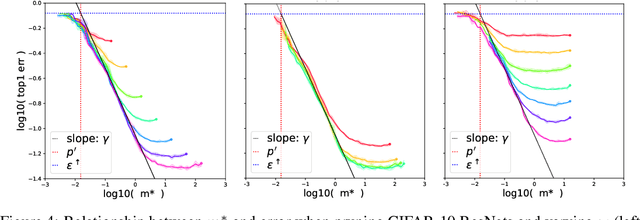
We show that the error of magnitude-pruned networks follows a scaling law, and that this law is of a fundamentally different nature than that of unpruned networks. We functionally approximate the error of the pruned networks, showing that it is predictable in terms of an invariant tying width, depth, and pruning level, such that networks of vastly different sparsities are freely interchangeable. We demonstrate the accuracy of this functional approximation over scales spanning orders of magnitude in depth, width, dataset size, and sparsity for CIFAR-10 and ImageNet. As neural networks become ever larger and more expensive to train, our findings enable a framework for reasoning conceptually and analytically about pruning.
View paper on
 OpenReview
OpenReview