 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen We First Met: Visual-Inertial Person Localization for Co-Robot Rendezvous
Paper and Code
Jun 17, 2020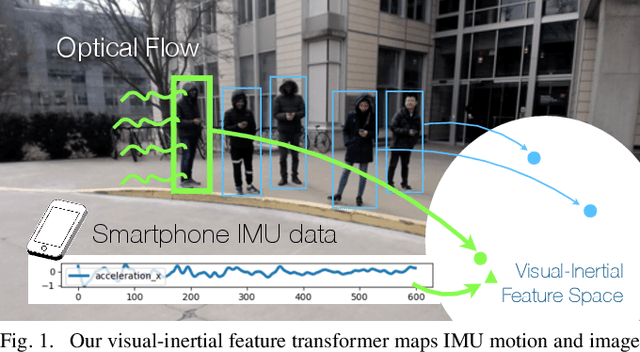

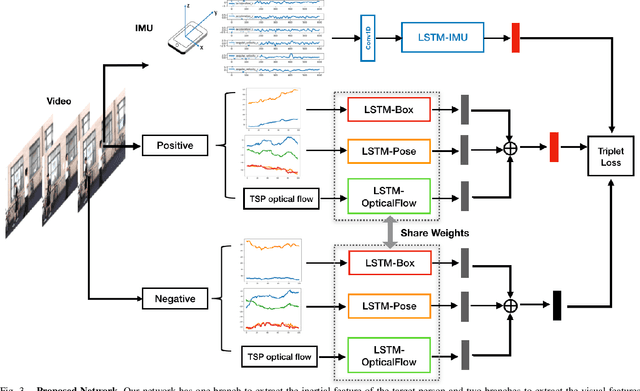
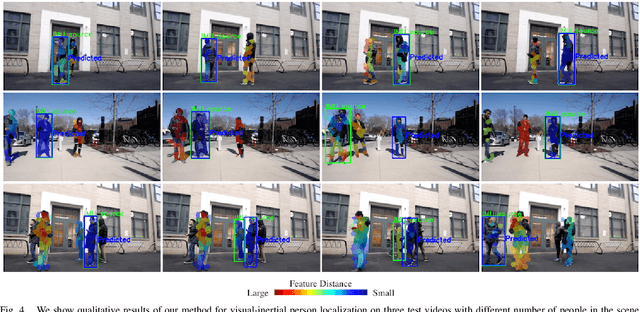
We aim to enable robots to visually localize a target person through the aid of an additional sensing modality -- the target person's 3D inertial measurements. The need for such technology may arise when a robot is to meet person in a crowd for the first time or when an autonomous vehicle must rendezvous with a rider amongst a crowd without knowing the appearance of the person in advance. A person's inertial information can be measured with a wearable device such as a smart-phone and can be shared selectively with an autonomous system during the rendezvous. We propose a method to learn a visual-inertial feature space in which the motion of a person in video can be easily matched to the motion measured by a wearable inertial measurement unit (IMU). The transformation of the two modalities into the joint feature space is learned through the use of a contrastive loss which forces inertial motion features and video motion features generated by the same person to lie close in the joint feature space. To validate our approach, we compose a dataset of over 60,000 video segments of moving people along with wearable IMU data. Our experiments show that our proposed method is able to accurately localize a target person with 80.7% accuracy using only 5 seconds of IMU data and video.