 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth by Poking: Learning to Estimate Depth from Self-Supervised Grasping
Paper and Code
Jun 16, 2020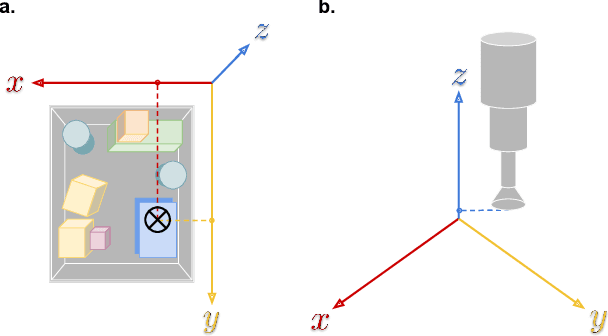


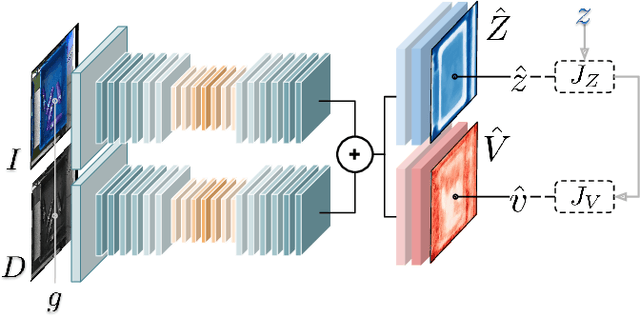
Accurate depth estimation remains an open problem for robotic manipulation; even state of the art techniques including structured light and LiDAR sensors fail on reflective or transparent surfaces. We address this problem by training a neural network model to estimate depth from RGB-D images, using labels from physical interactions between a robot and its environment. Our network predicts, for each pixel in an input image, the z position that a robot's end effector would reach if it attempted to grasp or poke at the corresponding position. Given an autonomous grasping policy, our approach is self-supervised as end effector position labels can be recovered through forward kinematics, without human annotation. Although gathering such physical interaction data is expensive, it is necessary for training and routine operation of state of the art manipulation systems. Therefore, this depth estimator comes ``for free'' while collecting data for other tasks (e.g., grasping, pushing, placing). We show our approach achieves significantly lower root mean squared error than traditional structured light sensors and unsupervised deep learning methods on difficult, industry-scale jumbled bin datasets.