 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic First-Order Algorithmic Framework for Bi-Level Programming Beyond Lower-Level Singleton
Paper and Code
Jul 02, 2020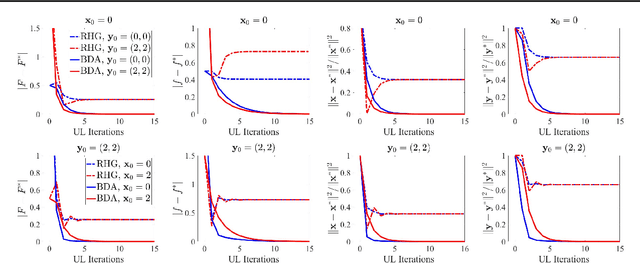
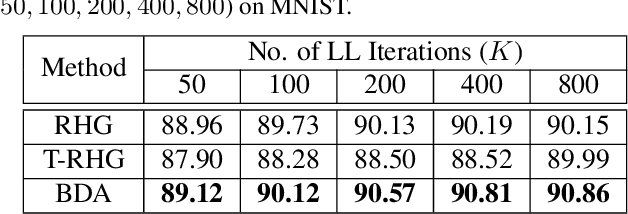

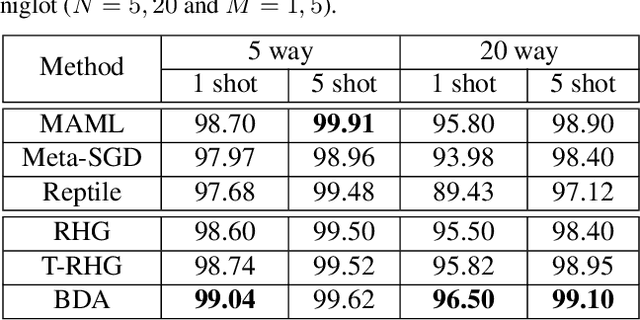
In recent years, a variety of gradient-based first-order methods have been developed to solve bi-level optimization problems for learning applications. However, theoretical guarantees of these existing approaches heavily rely on the simplification that for each fixed upper-level variable, the lower-level solution must be a singleton (a.k.a., Lower-Level Singleton, LLS). In this work, we first design a counter-example to illustrate the invalidation of such LLS condition. Then by formulating BLPs from the view point of optimistic bi-level and aggregating hierarchical objective information, we establish Bi-level Descent Aggregation (BDA), a flexible and modularized algorithmic framework for generic bi-level optimization. Theoretically, we derive a new methodology to prove the convergence of BDA without the LLS condition. Our investigations also demonstrate that BDA is indeed compatible to a verify of particular first-order computation modules. Additionally, as an interesting byproduct, we also improve these conventional first-order bi-level schemes (under the LLS simplification). Particularly, we establish their convergences with weaker assumptions. Extensive experiments justify our theoretical results and demonstrate the superiority of the proposed BDA for different tasks, including hyper-parameter optimization and meta learning.