 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Predictive Power of Neural Language Models for Human Real-Time Comprehension Behavior
Paper and Code
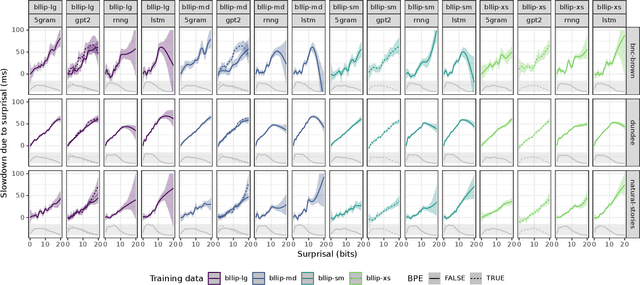
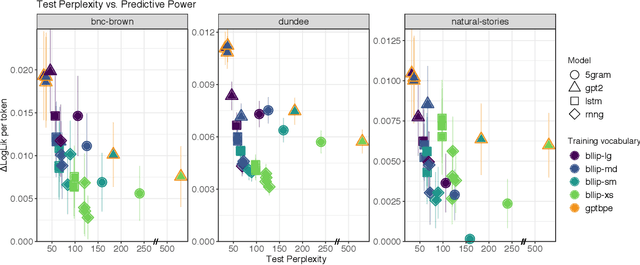
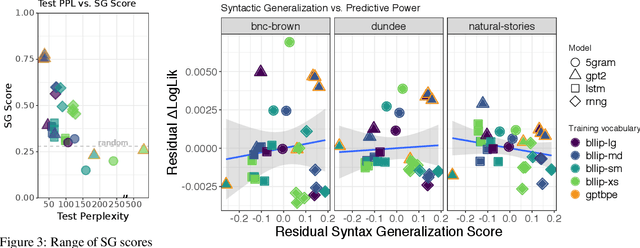
Human reading behavior is tuned to the statistics of natural language: the time it takes human subjects to read a word can be predicted from estimates of the word's probability in context. However, it remains an open question what computational architecture best characterizes the expectations deployed in real time by humans that determine the behavioral signatures of reading. Here we test over two dozen models, independently manipulating computational architecture and training dataset size, on how well their next-word expectations predict human reading time behavior on naturalistic text corpora. We find that across model architectures and training dataset sizes the relationship between word log-probability and reading time is (near-)linear. We next evaluate how features of these models determine their psychometric predictive power, or ability to predict human reading behavior. In general, the better a model's next-word expectations, the better its psychometric predictive power. However, we find nontrivial differences across model architectures. For any given perplexity, deep Transformer models and n-gram models generally show superior psychometric predictive power over LSTM or structurally supervised neural models, especially for eye movement data. Finally, we compare models' psychometric predictive power to the depth of their syntactic knowledge, as measured by a battery of syntactic generalization tests developed using methods from controlled psycholinguistic experiments. Once perplexity is controlled for, we find no significant relationship between syntactic knowledge and predictive power. These results suggest that different approaches may be required to best model human real-time language comprehension behavior in naturalistic reading versus behavior for controlled linguistic materials designed for targeted probing of syntactic knowledge.