 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Speaker Diarization with Speaker-Wise Chain Rule
Paper and Code
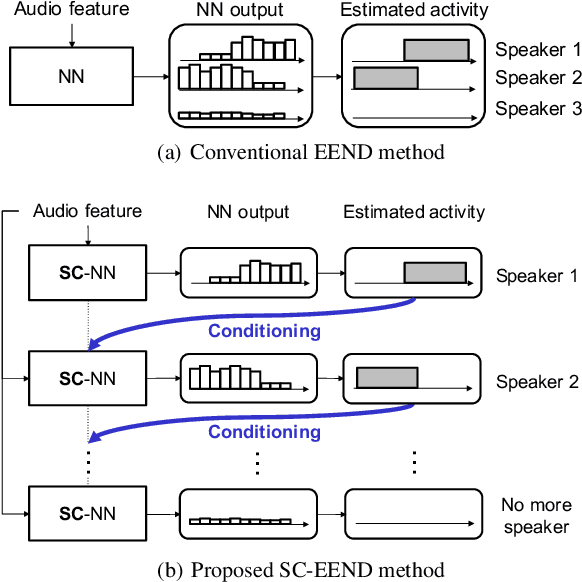
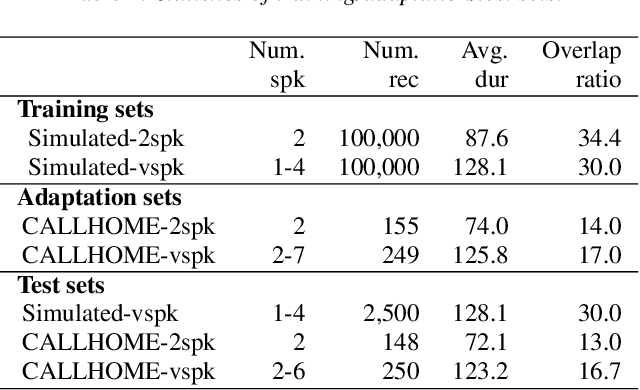
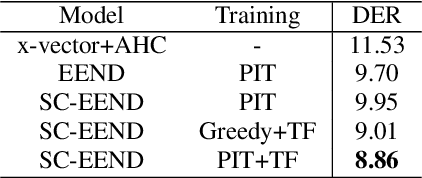
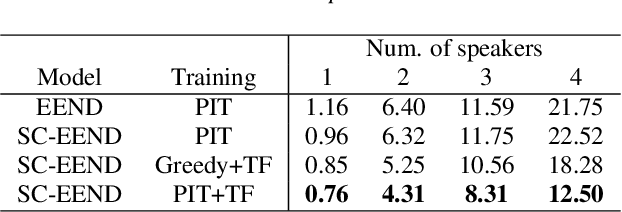
Speaker diarization is an essential step for processing multi-speaker audio. Although an end-to-end neural diarization (EEND) method achieved state-of-the-art performance, it is limited to a fixed number of speakers. In this paper, we solve this fixed number of speaker issue by a novel speaker-wise conditional inference method based on the probabilistic chain rule. In the proposed method, each speaker's speech activity is regarded as a single random variable, and is estimated sequentially conditioned on previously estimated other speakers' speech activities. Similar to other sequence-to-sequence models, the proposed method produces a variable number of speakers with a stop sequence condition. We evaluated the proposed method on multi-speaker audio recordings of a variable number of speakers. Experimental results show that the proposed method can correctly produce diarization results with a variable number of speakers and outperforms the state-of-the-art end-to-end speaker diarization methods in terms of diarization error rate.