 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaSGD: Squeezing SGD Parallelization Performance in Distributed Training Using Delayed Averaging
Paper and Code
May 31, 2020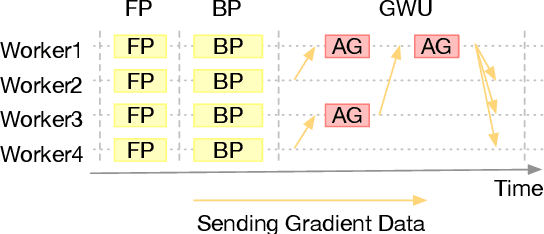
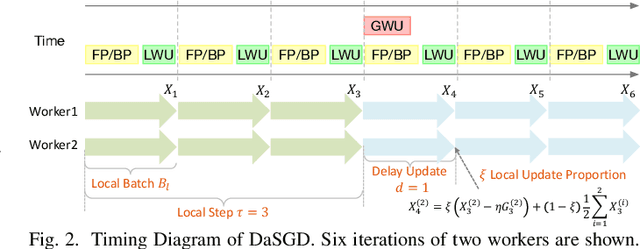
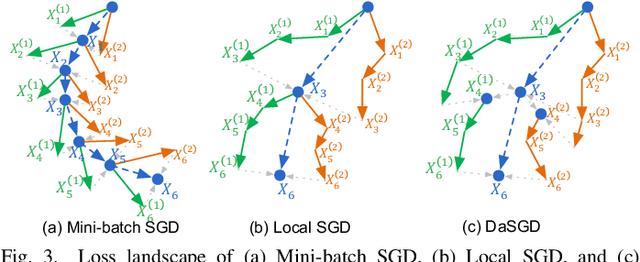
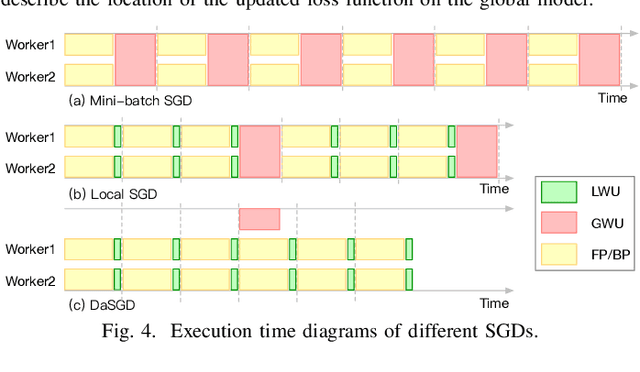
The state-of-the-art deep learning algorithms rely on distributed training systems to tackle the increasing sizes of models and training data sets. Minibatch stochastic gradient descent (SGD) algorithm requires workers to halt forward/back propagations, to wait for gradients aggregated from all workers, and to receive weight updates before the next batch of tasks. This synchronous execution model exposes the overheads of gradient/weight communication among a large number of workers in a distributed training system. We propose a new SGD algorithm, DaSGD (Local SGD with Delayed Averaging), which parallelizes SGD and forward/back propagations to hide 100% of the communication overhead. By adjusting the gradient update scheme, this algorithm uses hardware resources more efficiently and reduces the reliance on the low-latency and high-throughput inter-connects. The theoretical analysis and the experimental results show its convergence rate O(1/sqrt(K)), the same as SGD. The performance evaluation demonstrates it enables a linear performance scale-up with the cluster size.