 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Optimized Video Compression with MV-Residual Prediction
Paper and Code
May 26, 2020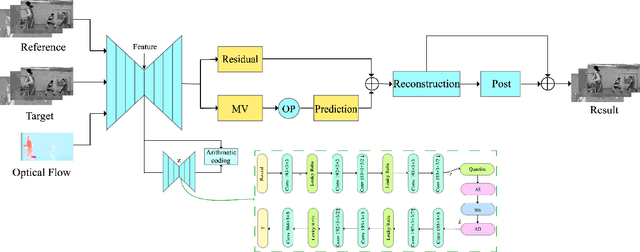

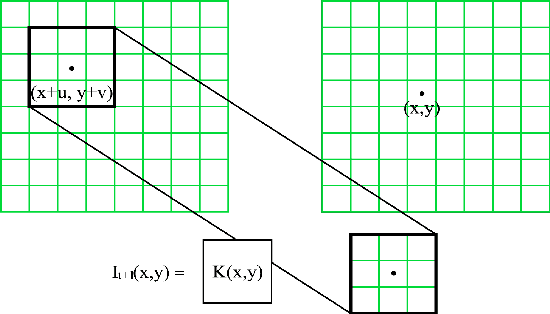
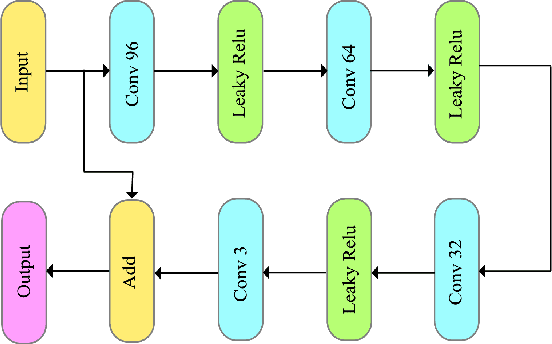
We present an end-to-end trainable framework for P-frame compression in this paper. A joint motion vector (MV) and residual prediction network MV-Residual is designed to extract the ensembled features of motion representations and residual information by treating the two successive frames as inputs. The prior probability of the latent representations is modeled by a hyperprior autoencoder and trained jointly with the MV-Residual network. Specially, the spatially-displaced convolution is applied for video frame prediction, in which a motion kernel for each pixel is learned to generate predicted pixel by applying the kernel at a displaced location in the source image. Finally, novel rate allocation and post-processing strategies are used to produce the final compressed bits, considering the bits constraint of the challenge. The experimental results on validation set show that the proposed optimized framework can generate the highest MS-SSIM for P-frame compression competition.