 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Sample Size Barrier in Model-Based Reinforcement Learning with a Generative Model
Paper and Code
Jun 17, 2020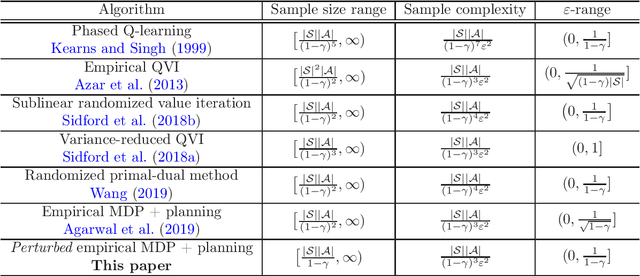
We investigate the sample efficiency of reinforcement learning in a $\gamma$-discounted infinite-horizon Markov decision process (MDP) with state space $\mathcal{S}$ and action space $\mathcal{A}$, assuming access to a generative model. Despite a number of prior work tackling this problem, a complete picture of the trade-offs between sample complexity and statistical accuracy is yet to be determined. In particular, prior results suffer from a sample size barrier, in the sense that their claimed statistical guarantees hold only when the sample size exceeds at least $\frac{|\mathcal{S}||\mathcal{A}|}{(1-\gamma)^2}$ (up to some log factor). The current paper overcomes this barrier by certifying the minimax optimality of model-based reinforcement learning as soon as the sample size exceeds the order of $\frac{|\mathcal{S}||\mathcal{A}|}{1-\gamma}$ (modulo some log factor). More specifically, a perturbed model-based planning algorithm provably finds an $\varepsilon$-optimal policy with an order of $\frac{|\mathcal{S}||\mathcal{A}| }{(1-\gamma)^3\varepsilon^2}\log\frac{|\mathcal{S}||\mathcal{A}|}{(1-\gamma)\varepsilon}$ samples for any $\varepsilon \in (0, \frac{1}{1-\gamma}]$. Along the way, we derive improved (instance-dependent) guarantees for model-based policy evaluation. To the best of our knowledge, this work provides the first minimax-optimal guarantee in a generative model that accommodates the entire range of sample sizes (beyond which finding a meaningful policy is information theoretically impossible).