 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGVNet: Attention Guided Velocity Learning for 3D Human Motion Prediction
Paper and Code
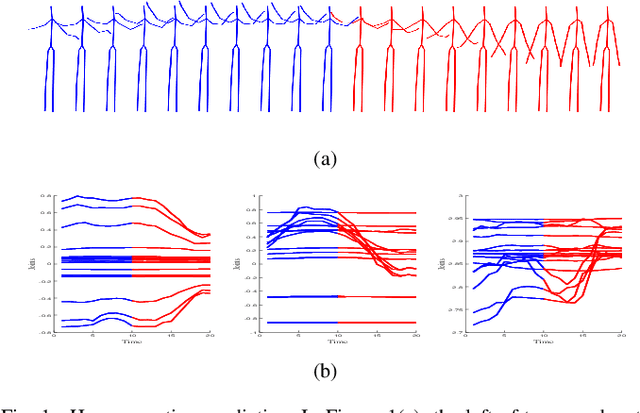
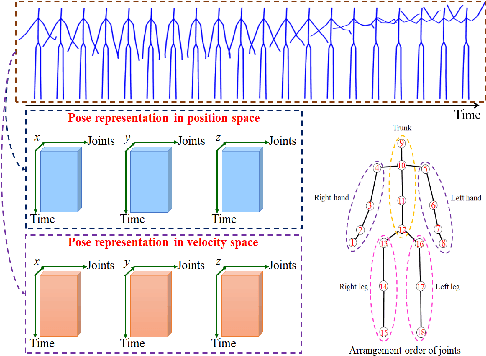
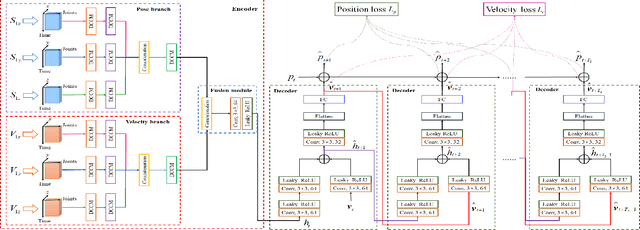
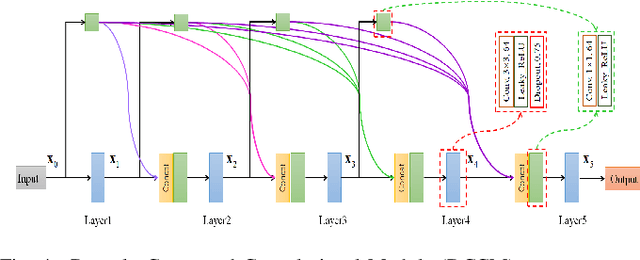
Prediction of human motion plays a significant role in human-machine interactions for a variety of real-life applications. In this paper, we propose a novel attention-guided velocity learning network, AGVNet, that utilizes multi-order information such as positions and velocities derived from the dynamic states of the human body for predicting human motion. Unlike existing methods, our network formulates the human motion system as a dynamic system and predicts human motion using the position and velocity of poses. Specifically, a multi-level Encoder is proposed to model the dynamics of moving joints at the axis level and joint level. A recursive feedforward Decoder generates future poses recursively by reusing the predictions at the previous time-steps and fusing multiple order information from both the velocity and position space. To avoid the error accumulation, a unique loss function, ATPL (Attention Temporal Prediction Loss), is designed with decreasing attention to the later predictions, making the network more accurate for predictions at the early time-steps. The experiments on two benchmark datasets (i.e., Human$3.6$M and $3$DPW) confirm that our method achieves state-of-the-art performance with improved effectiveness. The code will be made public once the paper is accepted.