 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification and Clustering of arXiv Documents, Sections, and Abstracts, Comparing Encodings of Natural and Mathematical Language
Paper and Code
May 22, 2020
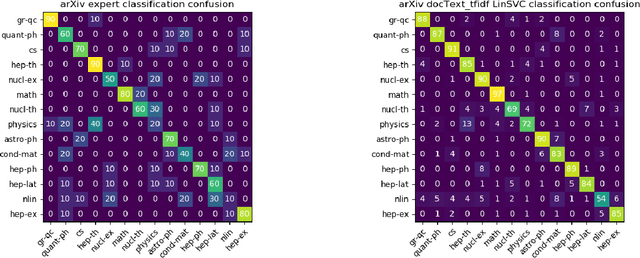

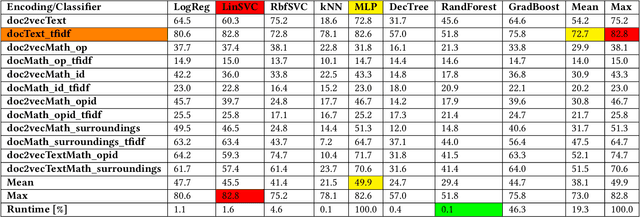
In this paper, we show how selecting and combining encodings of natural and mathematical language affect classification and clustering of documents with mathematical content. We demonstrate this by using sets of documents, sections, and abstracts from the arXiv preprint server that are labeled by their subject class (mathematics, computer science, physics, etc.) to compare different encodings of text and formulae and evaluate the performance and runtimes of selected classification and clustering algorithms. Our encodings achieve classification accuracies up to $82.8\%$ and cluster purities up to $69.4\%$ (number of clusters equals number of classes), and $99.9\%$ (unspecified number of clusters) respectively. We observe a relatively low correlation between text and math similarity, which indicates the independence of text and formulae and motivates treating them as separate features of a document. The classification and clustering can be employed, e.g., for document search and recommendation. Furthermore, we show that the computer outperforms a human expert when classifying documents. Finally, we evaluate and discuss multi-label classification and formula semantification.