 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplified Self-Attention for Transformer-based End-to-End Speech Recognition
Paper and Code
May 21, 2020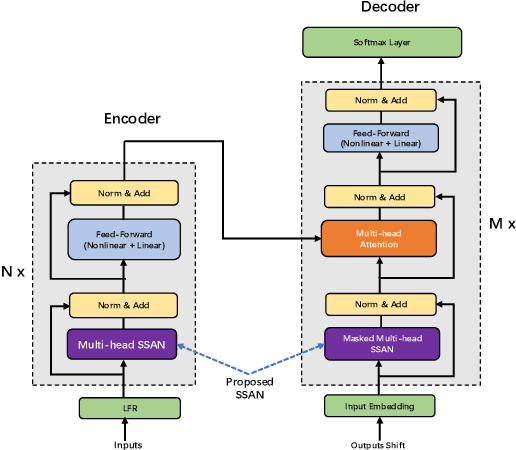
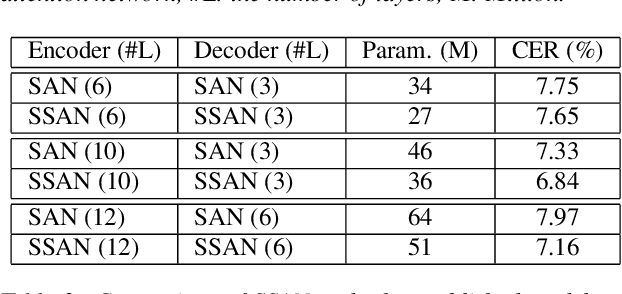
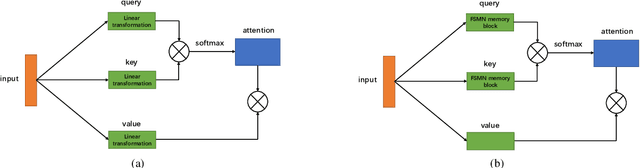
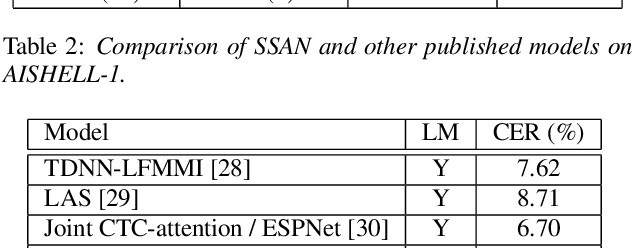
Transformer models have been introduced into end-to-end speech recognition with state-of-the-art performance on various tasks owing to their superiority in modeling long-term dependencies. However, such improvements are usually obtained through the use of very large neural networks. Transformer models mainly include two submodules - position-wise feedforward layers and self-attention (SAN) layers. In this paper, to reduce the model complexity while maintaining good performance, we propose a simplified self-attention (SSAN) layer which employs FSMN memory block instead of projection layers to form query and key vectors for transformer-based end-to-end speech recognition. We evaluate the SSAN-based and the conventional SAN-based transformers on the public AISHELL-1, internal 1000-hour and 20,000-hour large-scale Mandarin tasks. Results show that our proposed SSAN-based transformer model can achieve over 20% relative reduction in model parameters and 6.7% relative CER reduction on the AISHELL-1 task. With impressively 20% parameter reduction, our model shows no loss of recognition performance on the 20,000-hour large-scale task.