 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation
Paper and Code
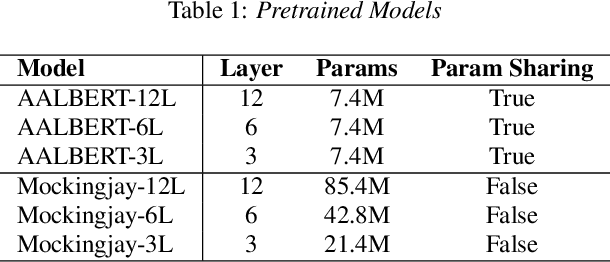
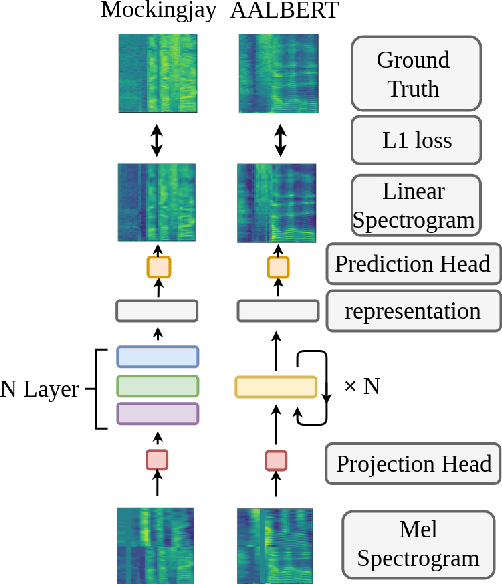
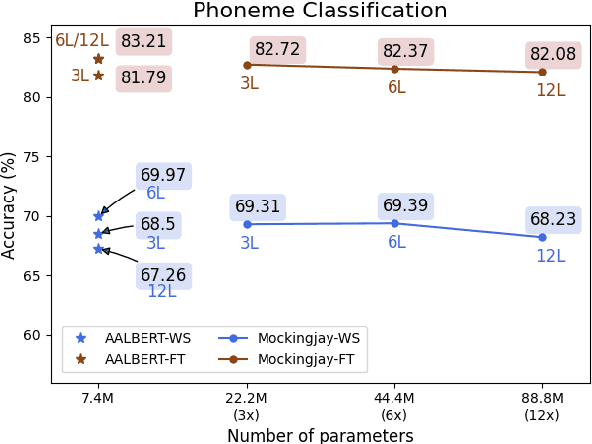
For self-supervised speech processing, it is crucial to use pretrained models as speech representation extractors. In recent works, increasing the size of the model has been utilized in acoustic model training in order to achieve better performance. In this paper, we propose Audio ALBERT, a lite version of the self-supervised speech representation model. We use the representations with two downstream tasks, speaker identification, and phoneme classification. We show that Audio ALBERT is capable of achieving competitive performance with those huge models in the downstream tasks while utilizing 91\% fewer parameters. Moreover, we use some simple probing models to measure how much the information of the speaker and phoneme is encoded in latent representations. In probing experiments, we find that the latent representations encode richer information of both phoneme and speaker than that of the last layer.