 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Visual Object Tracking with Two-Stream Residual Convolutional Networks
Paper and Code
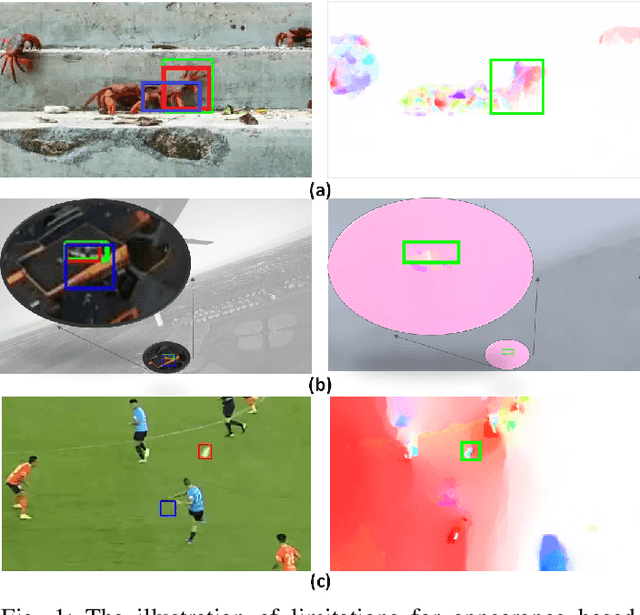
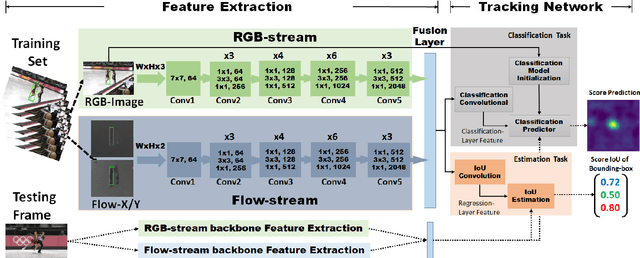

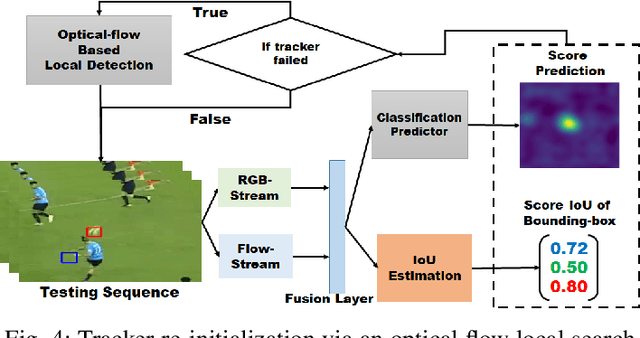
The current deep learning based visual tracking approaches have been very successful by learning the target classification and/or estimation model from a large amount of supervised training data in offline mode. However, most of them can still fail in tracking objects due to some more challenging issues such as dense distractor objects, confusing background, motion blurs, and so on. Inspired by the human "visual tracking" capability which leverages motion cues to distinguish the target from the background, we propose a Two-Stream Residual Convolutional Network (TS-RCN) for visual tracking, which successfully exploits both appearance and motion features for model update. Our TS-RCN can be integrated with existing deep learning based visual trackers. To further improve the tracking performance, we adopt a "wider" residual network ResNeXt as its feature extraction backbone. To the best of our knowledge, TS-RCN is the first end-to-end trainable two-stream visual tracking system, which makes full use of both appearance and motion features of the target. We have extensively evaluated the TS-RCN on most widely used benchmark datasets including VOT2018, VOT2019, and GOT-10K. The experiment results have successfully demonstrated that our two-stream model can greatly outperform the appearance based tracker, and it also achieves state-of-the-art performance. The tracking system can run at up to 38.1 FPS.