 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Model Inversion and Membership Inference Attacks via Prediction Purification
Paper and Code
May 08, 2020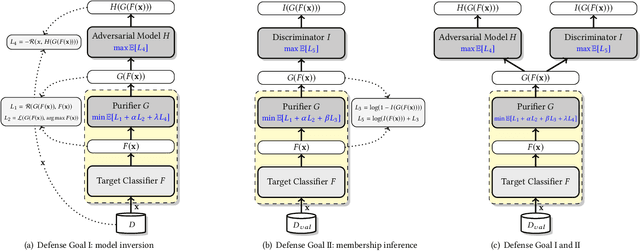
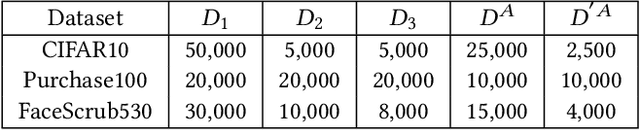
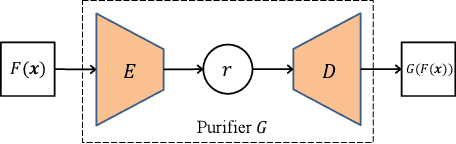
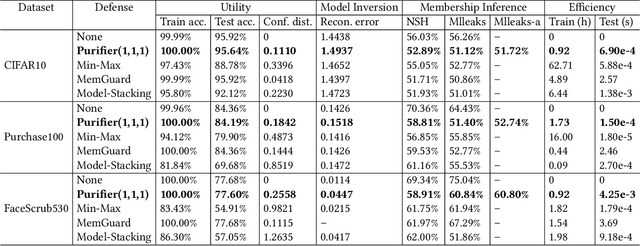
Neural networks are susceptible to data inference attacks such as the model inversion attack and the membership inference attack, where the attacker could infer the reconstruction and the membership of a data sample from the confidence scores predicted by the target classifier. In this paper, we propose a common approach, namely purification framework, to defend data inference attacks. It purifies the confidence score vectors predicted by the target classifier, with the goal of removing redundant information that could be exploited by the attacker to perform the inferences. Specifically, we design a purifier model which takes a confidence score vector as input and reshapes it to meet the defense goals. It does not retrain the target classifier. The purifier can be used to mitigate the model inversion attack, the membership inference attack or both attacks. We evaluate our approach on deep neural networks using benchmark datasets. We show that the purification framework can effectively defend the model inversion attack and the membership inference attack, while introducing negligible utility loss to the target classifier (e.g., less than 0.3% classification accuracy drop). Moreover, we also empirically show that it is possible to defend data inference attacks with negligible change to the generalization ability of the classification function.