 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Question Abstraction and Retrieval for Data-Scarce Semantic Parsing
Paper and Code


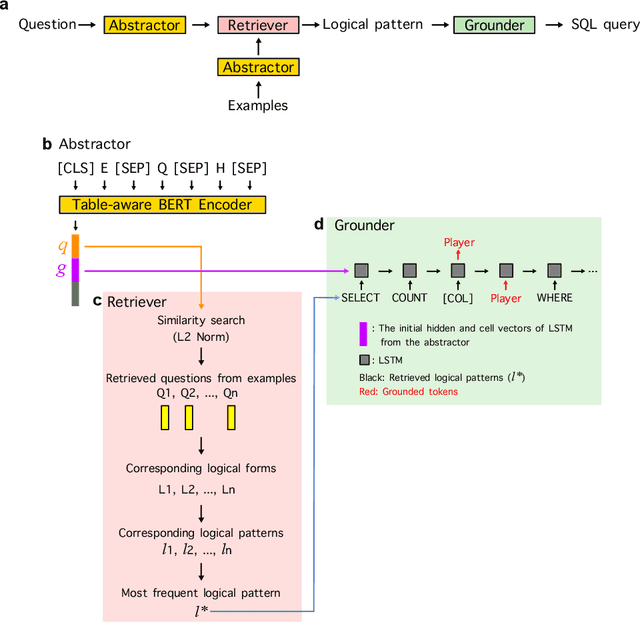

Deep learning approaches to semantic parsing require a large amount of labeled data, but annotating complex logical forms is costly. Here, we propose Syntactic Question Abstraction and Retrieval (SQAR), a method to build a neural semantic parser that translates a natural language (NL) query to a SQL logical form (LF) with less than 1,000 annotated examples. SQAR first retrieves a logical pattern from the train data by computing the similarity between NL queries and then grounds a lexical information on the retrieved pattern in order to generate the final LF. We validate SQAR by training models using various small subsets of WikiSQL train data achieving up to 4.9% higher LF accuracy compared to the previous state-of-the-art models on WikiSQL test set. We also show that by using query-similarity to retrieve logical pattern, SQAR can leverage a paraphrasing dataset achieving up to 5.9% higher LF accuracy compared to the case where SQAR is trained by using only WikiSQL data. In contrast to a simple pattern classification approach, SQAR can generate unseen logical patterns upon the addition of new examples without re-training the model. We also discuss an ideal way to create cost efficient and robust train datasets when the data distribution can be approximated under a data-hungry setting.