 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Dependency Parsing for 2D Document Understanding
Paper and Code
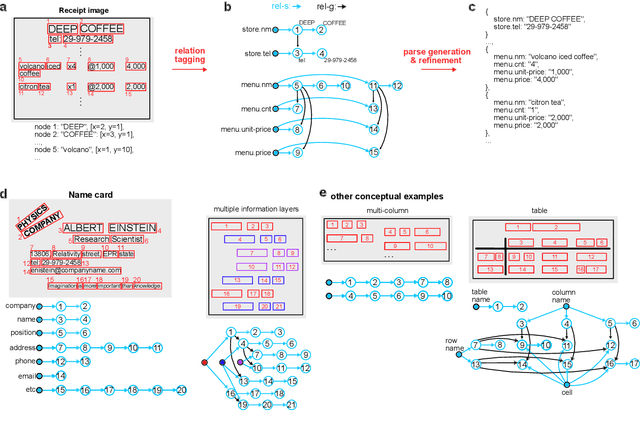

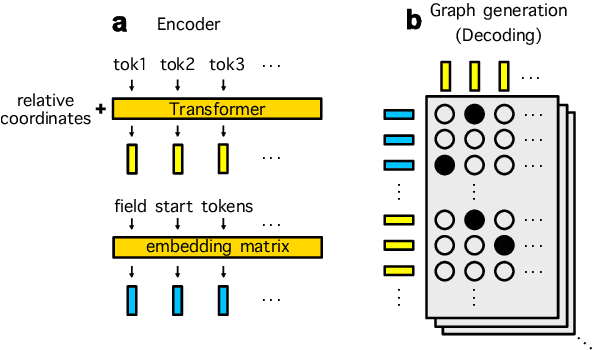
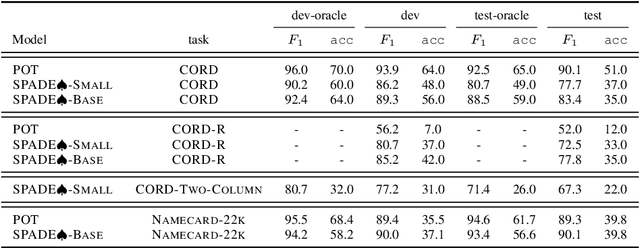
Information Extraction (IE) for document images is often approached as a BIO tagging problem, where the model sequentially goes through and classifies each recognized input token into one of the information categories. However, such problem setup has two inherent limitations that (1) it can only extract a flat list of information and (2) it assumes that the input data is serialized, often by a simple rule-based script. Nevertheless, real-world documents often contain hierarchical information in the form of two-dimensional language data in which the serialization can be highly non-trivial. To tackle these issues, we propose SPADE$\spadesuit$ (SPatial DEpendency parser), an end-to-end spatial dependency parser that is serializer-free and capable of modeling an arbitrary number of information layers, making it suitable for parsing structure-rich documents such as receipts and multimodal documents such as name cards. We show that SPADE$\spadesuit$ outperforms the previous BIO tagging-based approach on name card parsing task and achieves comparable performance on receipt parsing task. Especially, when the receipt images have non-flat manifold representing physical distortion of receipt paper in real-world, SPADE$\spadesuit$ outperforms the tagging-based method by a large margin of 25.8% highlighting the strong performance of SPADE$\spadesuit$ over spatially complex document.