 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Unsupervised Sentence Simplification
Paper and Code
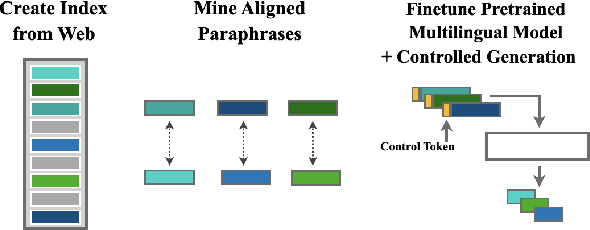

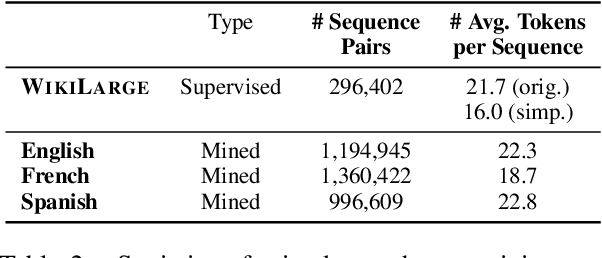
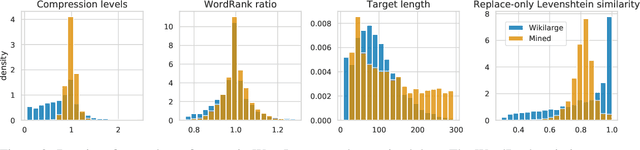
Progress in Sentence Simplification has been hindered by the lack of supervised data, particularly in languages other than English. Previous work has aligned sentences from original and simplified corpora such as English Wikipedia and Simple English Wikipedia, but this limits corpus size, domain, and language. In this work, we propose using unsupervised mining techniques to automatically create training corpora for simplification in multiple languages from raw Common Crawl web data. When coupled with a controllable generation mechanism that can flexibly adjust attributes such as length and lexical complexity, these mined paraphrase corpora can be used to train simplification systems in any language. We further incorporate multilingual unsupervised pretraining methods to create even stronger models and show that by training on mined data rather than supervised corpora, we outperform the previous best results. We evaluate our approach on English, French, and Spanish simplification benchmarks and reach state-of-the-art performance with a totally unsupervised approach. We will release our models and code to mine the data in any language included in Common Crawl.