 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Paper and Code
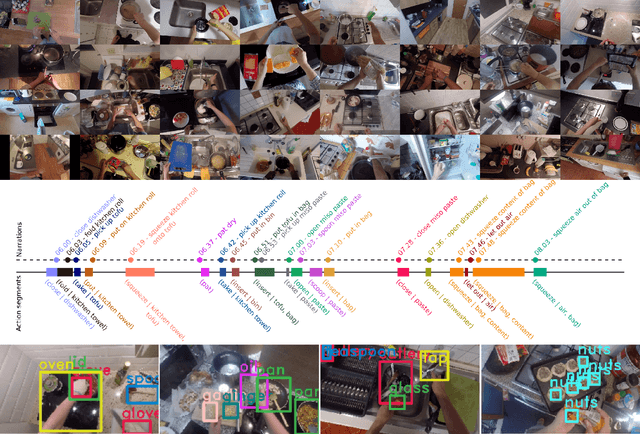
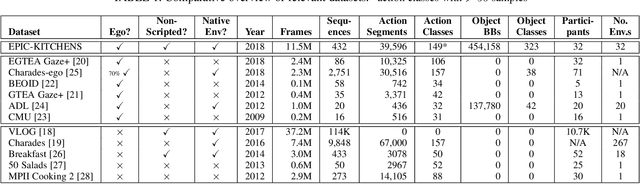

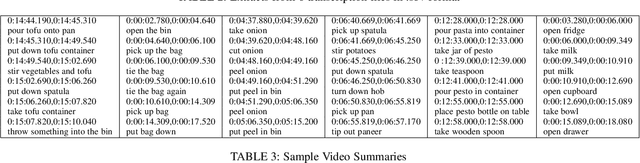
Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.