 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse, Dense, and Attentional Representations for Text Retrieval
Paper and Code
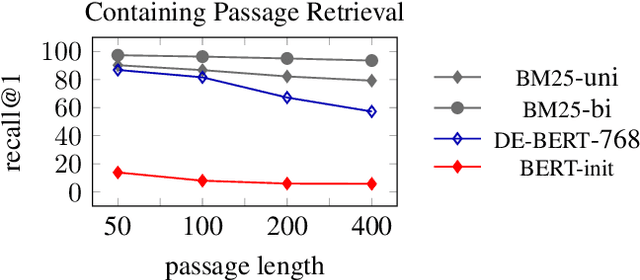
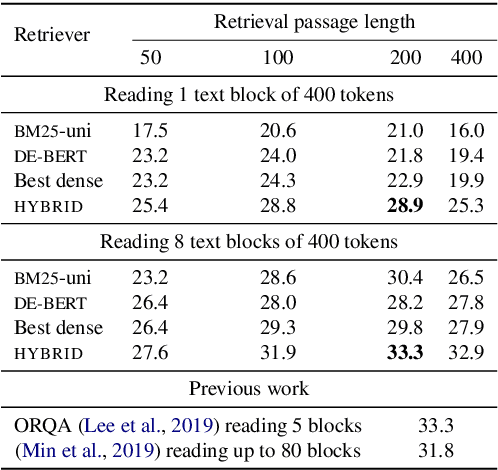
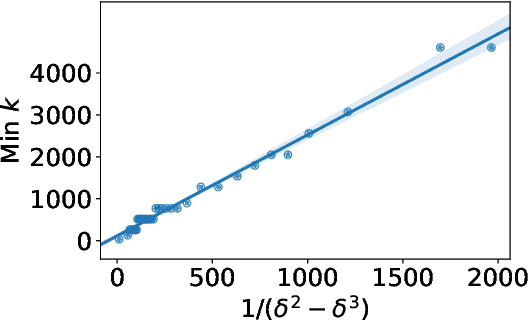
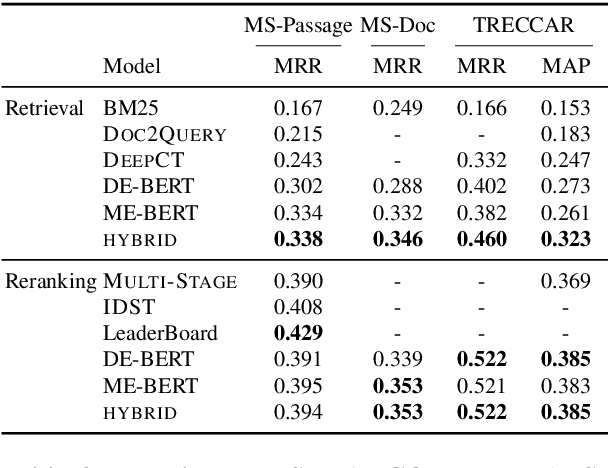
Dual encoder architectures perform retrieval by encoding documents and queries into dense low-dimensional vectors, and selecting the document that has the highest inner product with the query. We investigate the capacity of this architecture relative to sparse bag-of-words retrieval models and attentional neural networks. We establish new connections between the encoding dimension and the number of unique terms in each document and query, using both theoretical and empirical analysis. We show an upper bound on the encoding size, which may be unsustainably large for long documents. For cross-attention models, we show an upper bound using much smaller encodings per token, but such models are difficult to scale to realistic retrieval problems due to computational cost. Building on these insights, we propose a simple neural model that combines the efficiency of dual encoders with some of the expressiveness of attentional architectures, and explore a sparse-dense hybrid to capitalize on the precision of sparse retrieval. These models outperform strong alternatives in open retrieval.