 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Decisions Emerge across Layers in Neural Models? Interpretation with Differentiable Masking
Paper and Code
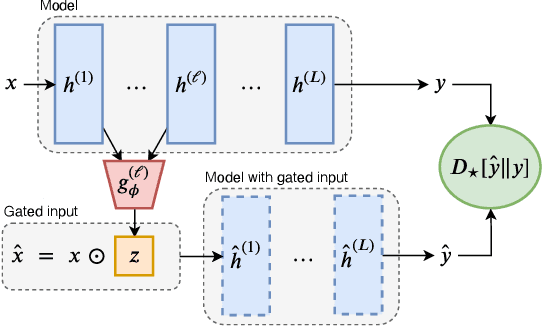
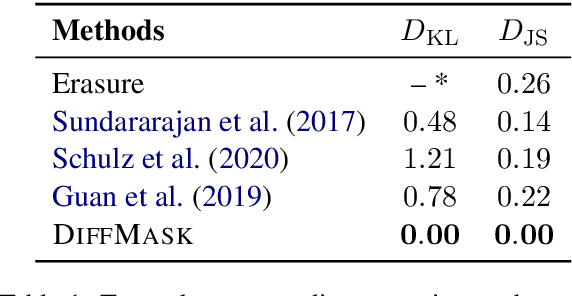

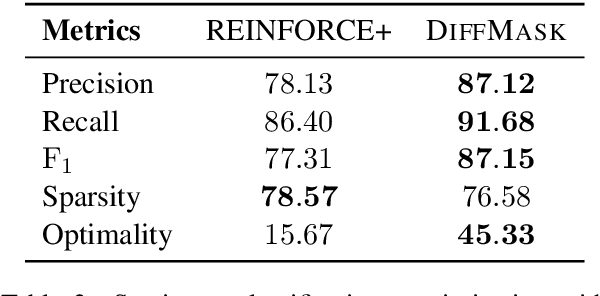
Attribution methods assess the contribution of inputs (e.g., words) to the model prediction. One way to do so is erasure: a subset of inputs is considered irrelevant if it can be removed without affecting the model prediction. Despite its conceptual simplicity, erasure is not commonly used in practice. First, the objective is generally intractable, and approximate search or leave-one-out estimates are typically used instead; both approximations may be inaccurate and remain very expensive with modern deep (e.g., BERT-based) NLP models. Second, the method is susceptible to the hindsight bias: the fact that a token can be dropped does not mean that the model `knows' it can be dropped. The resulting pruning is over-aggressive and does not reflect how the model arrives at the prediction. To deal with these two challenges, we introduce Differentiable Masking. DiffMask relies on learning sparse stochastic gates (i.e., masks) to completely mask-out subsets of the input while maintaining end-to-end differentiability. The decision to include or disregard an input token is made with a simple linear model based on intermediate hidden layers of the analyzed model. First, this makes the approach efficient at test time because we predict rather than search. Second, as with probing classifiers, this reveals what the network `knows' at the corresponding layers. This lets us not only plot attribution heatmaps but also analyze how decisions are formed across network layers. We use DiffMask to study BERT models on sentiment classification and question answering.