 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning for Abstractive Multi-Document Opinion Summarization
Paper and Code

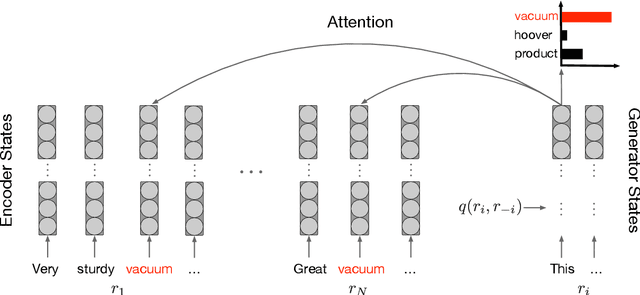
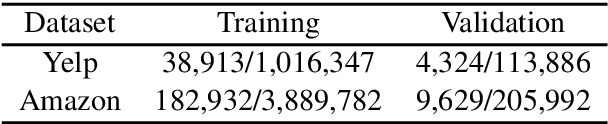
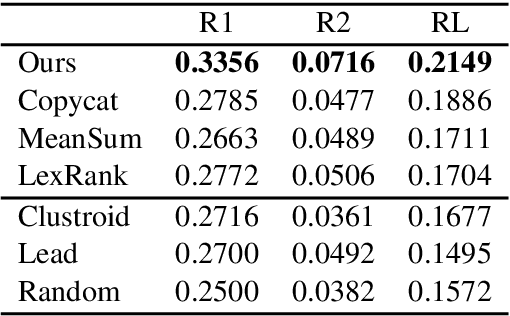
Opinion summarization is an automatic creation of text reflecting subjective information expressed in multiple documents, such as user reviews of a product. The task is practically important and has attracted a lot of attention. However, due to a high cost of summary production, datasets large enough for training supervised models are lacking. Instead, the task has been traditionally approached with extractive methods that learn to select text fragments in an unsupervised or weakly-supervised way. Recently, it has been shown that abstractive summaries, potentially more fluent and better at reflecting conflicting information, can also be produced in an unsupervised fashion. However, these models, not being exposed to the actual summaries, fail to capture their essential properties. In this work, we show that even a handful of summaries is sufficient to bootstrap generation of the summary text with all expected properties, such as writing style, informativeness, fluency, and sentiment preservation. We start by training a language model to generate a new product review given available reviews of the product. The model is aware of the properties: it proceeds with first generating property values and then producing a review conditioned on them. We do not use any summaries in this stage and the property values are derived from reviews with no manual effort. In the second stage, we fine-tune the module predicting the property values on a few available summaries. This lets us switch the generator to the summarization mode. Our approach substantially outperforms previous extractive and abstractive methods in automatic and human evaluation.