 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Focused Study to Compare Arabic Pre-training Models on Newswire IE Tasks
Paper and Code
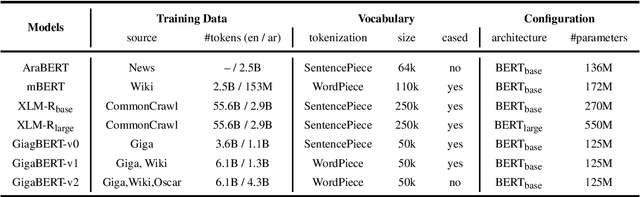
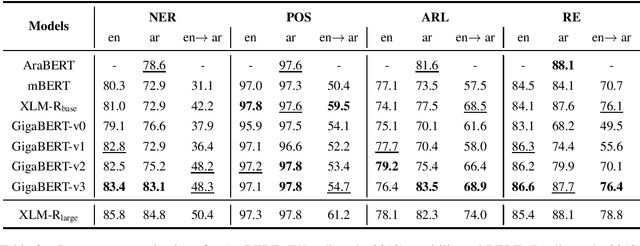
The Arabic language is a morphological rich language, posing many challenges for information extraction (IE) tasks, including Named Entity Recognition (NER), Part-of-Speech tagging (POS), Argument Role Labeling (ARL) and Relation Extraction (RE). A few multilingual pre-trained models have been proposed and show good performance for Arabic, however, most experiment results are reported on language understanding tasks, such as natural language inference, question answering and sentiment analysis. Their performance on the IE tasks is less known, in particular, the cross-lingual transfer capability from English to Arabic. In this work, we pre-train a Gigaword-based bilingual language model (GigaBERT) to study these two distant languages as well as zero-short transfer learning on the information extraction tasks. Our GigaBERT model can outperform mBERT and XLM-R-base on NER, POS and ARL tasks, with regarding to the per-language and/or zero-transfer performance. We make our pre-trained models publicly available at https://github.com/lanwuwei/GigaBERT to facilitate the research of this field.