 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGAIL: Generative Adversarial Imitation Learning for Text Generation
Paper and Code
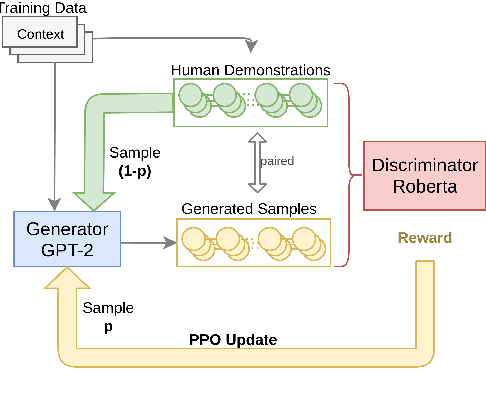

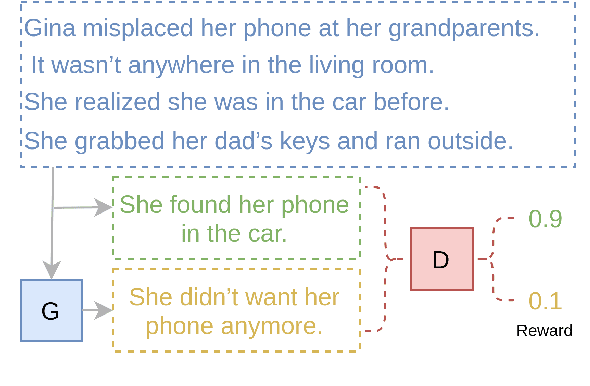
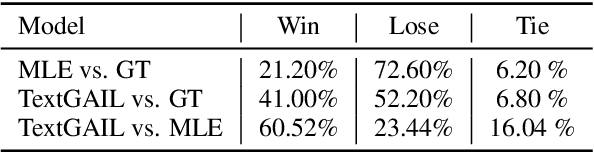
Exposure bias is one of the most challenging problems in text generation with maximum likelihood estimation (MLE) based methods. Previous studies try to tackle this problem by applying Generative Adversarial Networks. However, lacking sufficient language priors makes those methods perform worse than MLE-based methods. To address this problem, we propose TextGAIL, a generative adversarial imitation learning framework with large pretrained language models RoBERTa and GPT-2. We also leverage proximal policy optimization, and efficiently utilize human demonstrations to stabilize the generator's training. We evaluate TextGAIL on a story ending generation task on the ROCStories dataset. We introduce the Perception score to evaluate our model. Experiments show that with the help of the large pretrained language models, our proposed method can generate highly diverse and appropriate story endings. We release the code and generated outputs.