 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst return then explore
Paper and Code
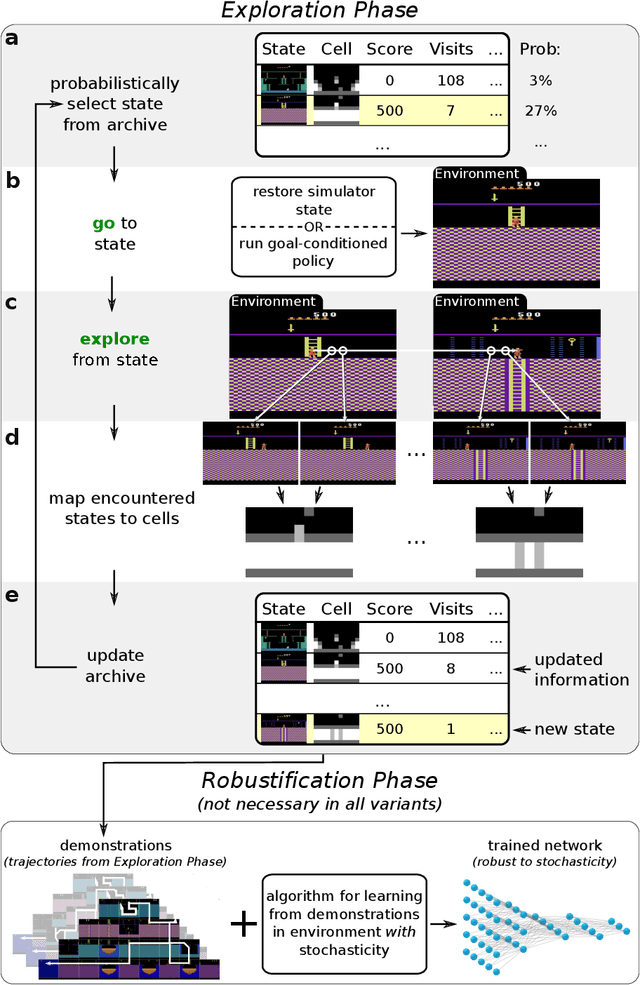
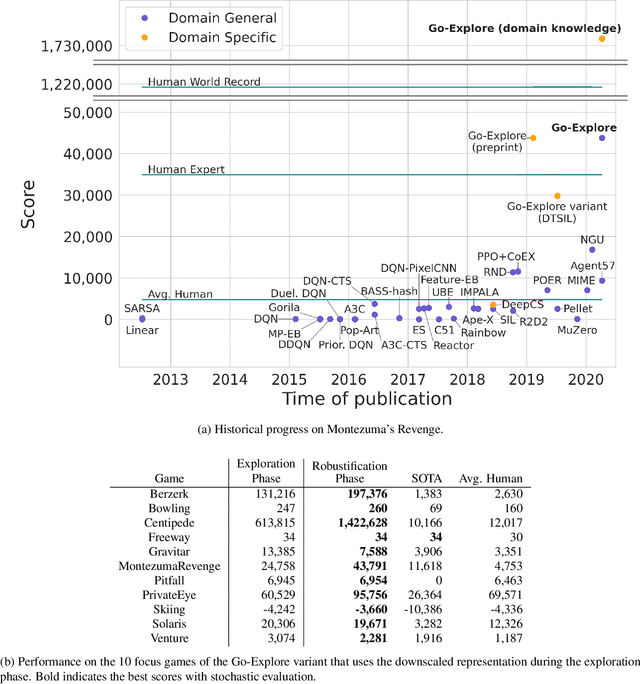
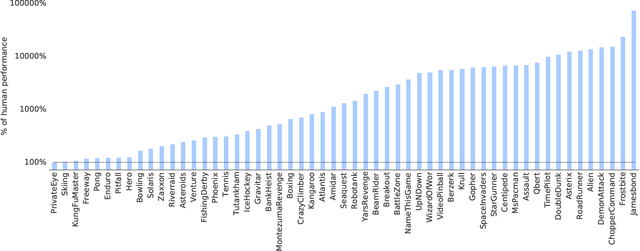
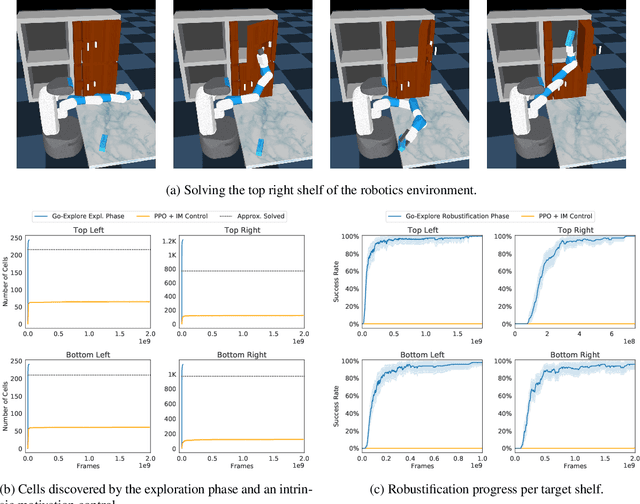
The promise of reinforcement learning is to solve complex sequential decision problems by specifying a high-level reward function only. However, RL algorithms struggle when, as is often the case, simple and intuitive rewards provide sparse and deceptive feedback. Avoiding these pitfalls requires thoroughly exploring the environment, but despite substantial investments by the community, creating algorithms that can do so remains one of the central challenges of the field. We hypothesize that the main impediment to effective exploration originates from algorithms forgetting how to reach previously visited states ("detachment") and from failing to first return to a state before exploring from it ("derailment"). We introduce Go-Explore, a family of algorithms that addresses these two challenges directly through the simple principles of explicitly remembering promising states and first returning to such states before exploring. Go-Explore solves all heretofore unsolved Atari games (those for which algorithms could not previously outperform humans when evaluated following current community standards) and surpasses the state of the art on all hard-exploration games, with orders of magnitude improvements on the grand challenges Montezuma's Revenge and Pitfall. We also demonstrate the practical potential of Go-Explore on a challenging and extremely sparse-reward robotics task. Additionally, we show that adding a goal-conditioned policy can further improve Go-Explore's exploration efficiency and enable it to handle stochasticity throughout training. The striking contrast between the substantial performance gains from Go-Explore and the simplicity of its mechanisms suggests that remembering promising states, returning to them, and exploring from them is a powerful and general approach to exploration, an insight that may prove critical to the creation of truly intelligent learning agents.