 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolution-Weight-Distribution Assumption: Rethinking the Criteria of Channel Pruning
Paper and Code
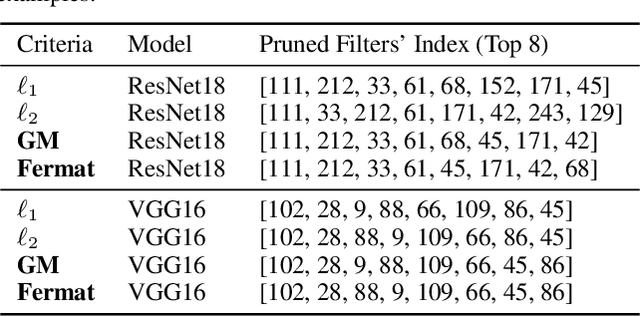
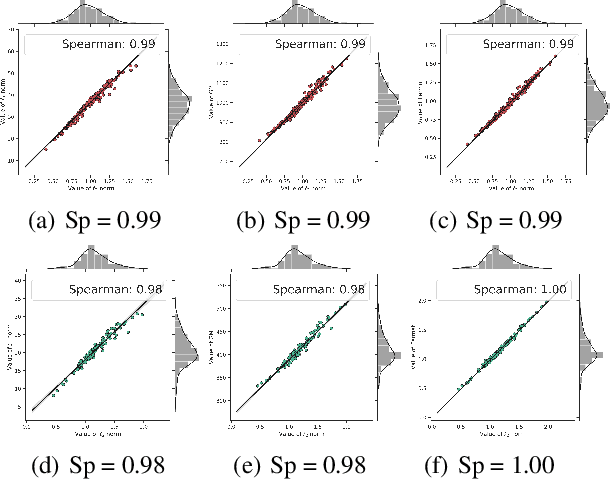
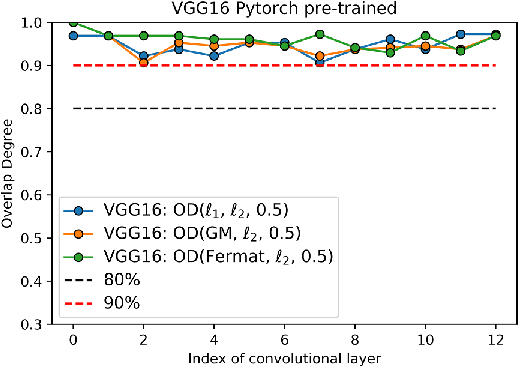

Channel pruning is one of the most important techniques for compressing neural networks with convolutional filters. However, in our study, we find strong similarities among some primary pruning criteria proposed in recent years. The sequence of filters'"importance" in a convolutional layer according to these criteria are almost the same, resulting in similar pruned structures. This finding can be explained by our assumption that the trained convolutional filters approximately follow a Gaussian-alike distribution, which is demonstrated through systematic and comprehensive statistical tests. Under this assumption, the similarity of these criteria is theoretically proved. Moreover, we also find that if the network has too much redundancy(exists a large number of filters in each convolutional layer), then these criteria can not distinguish the "importance" of the filters. This phenomenon is due to that the convolutional layer will form a special geometric structure when redundancy is large enough and our assumption holds: for every pair of filters in one layer, (1)Their $\ell_2$ norm are equivalent; (2)They are equidistant; (3)and they are orthogonal. The full appendix is released at https://github.com/dedekinds/CWDA.