 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue State Tracking with Pretrained Encoder for Multi-domain Trask-oriented Dialogue Systems
Paper and Code
Apr 22, 2020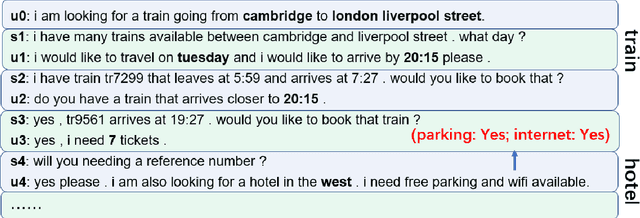
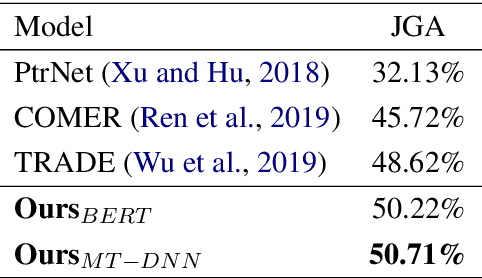
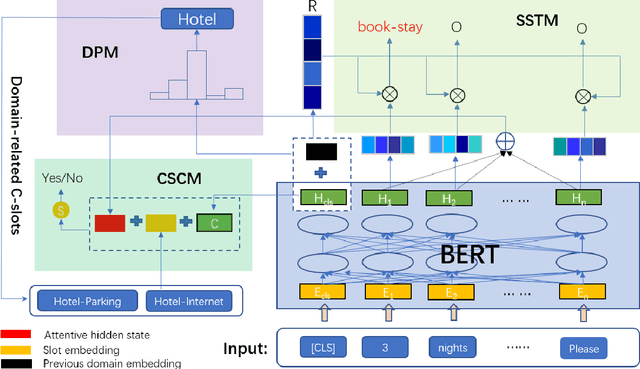
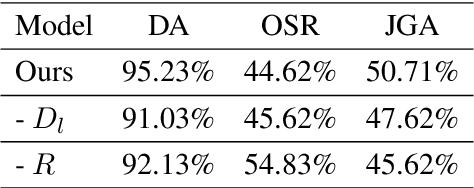
In task-oriented dialogue systems, Dialogue State Tracking (DST) is a core component, responsible for tracking users' goals over the whole course of a conversation, which then are utilized for deciding the next action to take. Recently proposed approaches either treat DST as a classification task by scoring all enumerated slot value pairs, or adopt encoder-decoder models to generate states, which fall short in tracking unknown slot values or hold a high computational complexity. In this work, we present a novel architecture, which decomposes the DST task into three sub-tasks to jointly extract dialogue states. Furthermore, we enhance our model with a pretrained language model and introduce domain-guided information to avoid predicting slots not belonging to the current domain. Experimental results on a multi-turn multi-domain dataset (MultiWoz) demonstrate the effectiveness of our proposed model, which outperforms previously reported results.