Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chinese Corpus for Fine-grained Entity Typing
Paper and Code

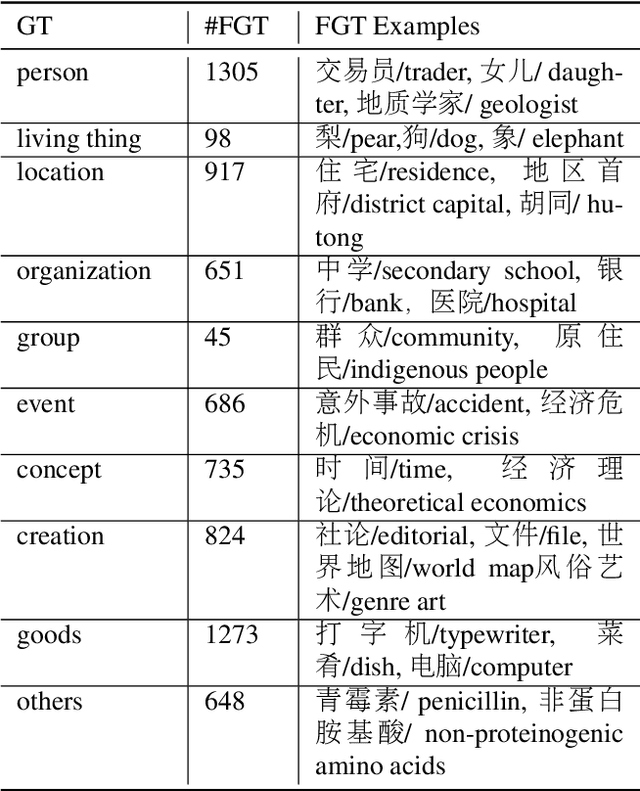
Fine-grained entity typing is a challenging task with wide applications. However, most existing datasets for this task are in English. In this paper, we introduce a corpus for Chinese fine-grained entity typing that contains 4,800 mentions manually labeled through crowdsourcing. Each mention is annotated with free-form entity types. To make our dataset useful in more possible scenarios, we also categorize all the fine-grained types into 10 general types. Finally, we conduct experiments with some neural models whose structures are typical in fine-grained entity typing and show how well they perform on our dataset. We also show the possibility of improving Chinese fine-grained entity typing through cross-lingual transfer learning.
* LREC 2020
View paper on