 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage Case Column Subset Selection for Entrywise $\ell_1$-Norm Loss
Paper and Code
Apr 16, 2020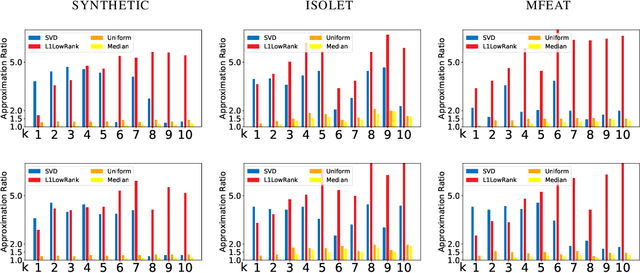
We study the column subset selection problem with respect to the entrywise $\ell_1$-norm loss. It is known that in the worst case, to obtain a good rank-$k$ approximation to a matrix, one needs an arbitrarily large $n^{\Omega(1)}$ number of columns to obtain a $(1+\epsilon)$-approximation to the best entrywise $\ell_1$-norm low rank approximation of an $n \times n$ matrix. Nevertheless, we show that under certain minimal and realistic distributional settings, it is possible to obtain a $(1+\epsilon)$-approximation with a nearly linear running time and poly$(k/\epsilon)+O(k\log n)$ columns. Namely, we show that if the input matrix $A$ has the form $A = B + E$, where $B$ is an arbitrary rank-$k$ matrix, and $E$ is a matrix with i.i.d. entries drawn from any distribution $\mu$ for which the $(1+\gamma)$-th moment exists, for an arbitrarily small constant $\gamma > 0$, then it is possible to obtain a $(1+\epsilon)$-approximate column subset selection to the entrywise $\ell_1$-norm in nearly linear time. Conversely we show that if the first moment does not exist, then it is not possible to obtain a $(1+\epsilon)$-approximate subset selection algorithm even if one chooses any $n^{o(1)}$ columns. This is the first algorithm of any kind for achieving a $(1+\epsilon)$-approximation for entrywise $\ell_1$-norm loss low rank approximation.