 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked GANs for Unsupervised Depth and Pose Prediction with Scale Consistency
Paper and Code
Apr 09, 2020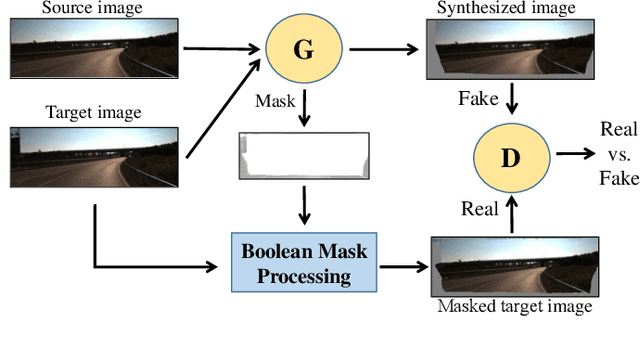

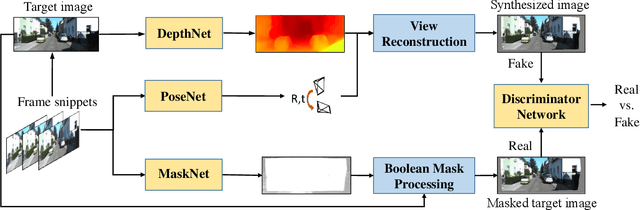

Previous works have shown that adversarial learning can be used for unsupervised monocular depth and visual odometry (VO) estimation. However, the performance of pose and depth networks is limited by occlusions and visual field changes. Because of the incomplete correspondence of visual information between frames caused by motion, target images cannot be synthesized completely from source images via view reconstruction and bilinear interpolation. The reconstruction loss based on the difference between synthesized and real target images will be affected by the incomplete reconstruction. Besides, the data distribution of unreconstructed regions will be learned and help the discriminator distinguish between real and fake images, thereby causing the case that the generator may fail to compete with the discriminator. Therefore, a MaskNet is designed in this paper to predict these regions and reduce their impacts on the reconstruction loss and adversarial loss. The impact of unreconstructed regions on discriminator is tackled by proposing a boolean mask scheme, as shown in Fig. 1. Furthermore, we consider the scale consistency of our pose network by utilizing a new scale-consistency loss, therefore our pose network is capable of providing the full camera trajectory over the long monocular sequence. Extensive experiments on KITTI dataset show that each component proposed in this paper contributes to the performance, and both of our depth and trajectory prediction achieve competitive performance.