 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC4D: A Sparse 4D Convolutional Network for Skeleton-Based Action Recognition
Paper and Code
Apr 07, 2020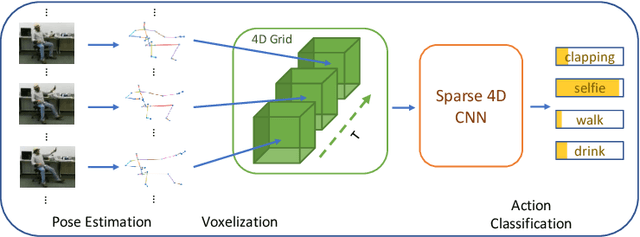

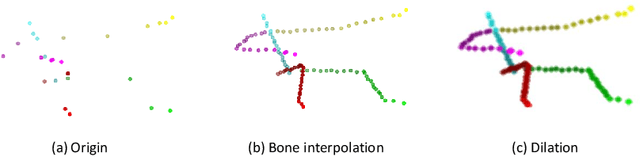
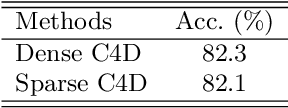
In this paper, a new perspective is presented for skeleton-based action recognition. Specifically, we regard the skeletal sequence as a spatial-temporal point cloud and voxelize it into a 4-dimensional grid. A novel sparse 4D convolutional network (SC4D) is proposed to directly process the generated 4D grid for high-level perceptions. Without manually designing the hand-crafted transformation rules, it makes better use of the advantages of the convolutional network, resulting in a more concise, general and robust framework for skeletal data. Besides, by processing the space and time simultaneously, it largely keeps the spatial-temporal consistency of the skeletal data, and thus brings better expressiveness. Moreover, with the help of the sparse tensor, it can be efficiently executed with less computations. To verify the superiority of SC4D, extensive experiments are conducted on two challenging datasets, namely, NTU-RGBD and SHREC, where SC4D achieves state-of-the-art performance on both of them.