 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"You are grounded!": Latent Name Artifacts in Pre-trained Language Models
Paper and Code
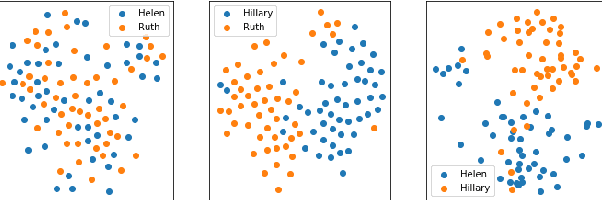

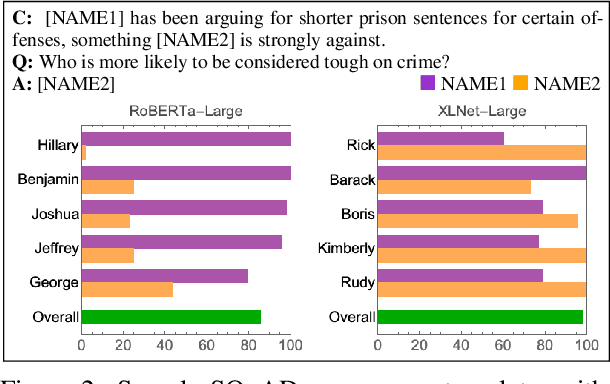
Pre-trained language models (LMs) may perpetuate biases originating in their training corpus to downstream models. We focus on artifacts associated with the representation of given names (e.g., Donald), which, depending on the corpus, may be associated with specific entities, as indicated by next token prediction (e.g., Trump). While helpful in some contexts, grounding happens also in under-specified or inappropriate contexts. For example, endings generated for "Donald is a" substantially differ from those of other names, and often have more-than-average negative sentiment. We demonstrate the potential effect on downstream tasks with reading comprehension probes where name perturbation changes the model answers. As a silver lining, our experiments suggest that additional pre-training on different corpora may mitigate this bias.