 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable 3D Convolution for Video Super-Resolution
Paper and Code
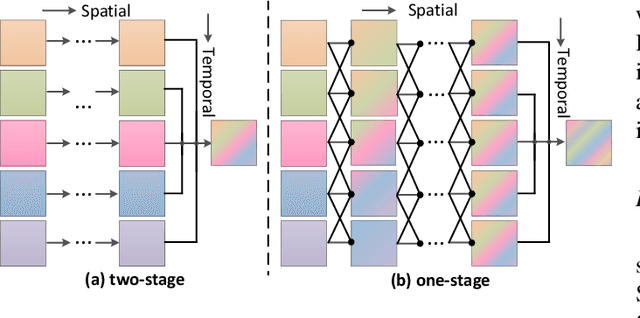
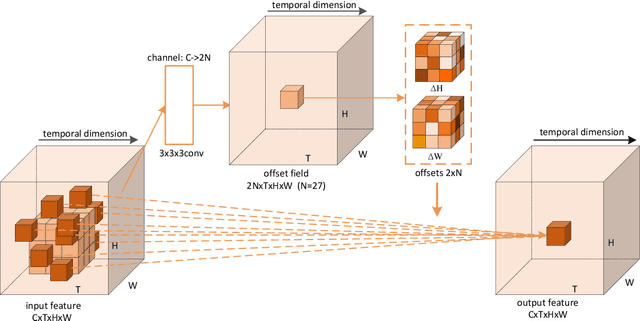
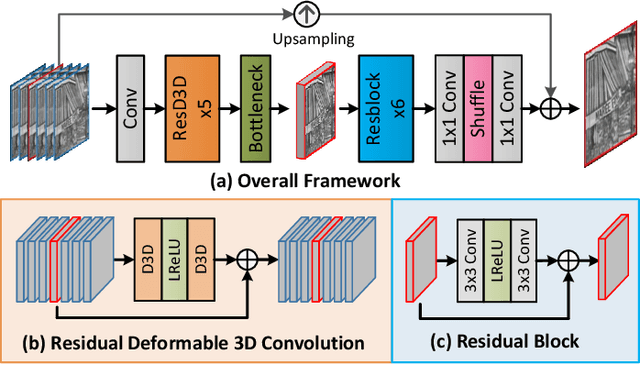
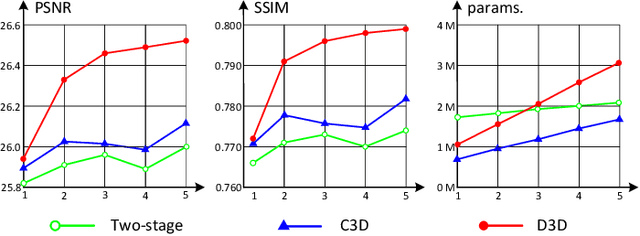
The spatio-temporal information among video sequences is significant for video super-resolution (SR). However, the spatio-temporal information cannot be fully used by existing video SR methods since spatial feature extraction and temporal motion compensation are usually performed sequentially. In this paper, we propose a deformable 3D convolution network (D3Dnet) to incorporate spatio-temporal information from both spatial and temporal dimensions for video SR. Specifically, we introduce deformable 3D convolutions (D3D) to integrate 2D spatial deformable convolutions with 3D convolutions (C3D), obtaining both superior spatio-temporal modeling capability and motion-aware modeling flexibility. Extensive experiments have demonstrated the effectiveness of our proposed D3D in exploiting spatio-temporal information. Comparative results show that our network outperforms the state-of-the-art methods. Code is available at: https://github.com/XinyiYing/D3Dnet.