 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Selection for Deep ReLU Nets in Feature Extraction and Generalization
Paper and Code
Apr 01, 2020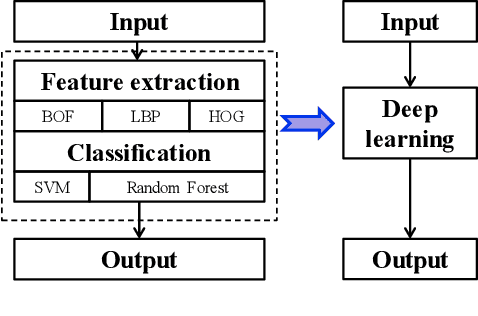
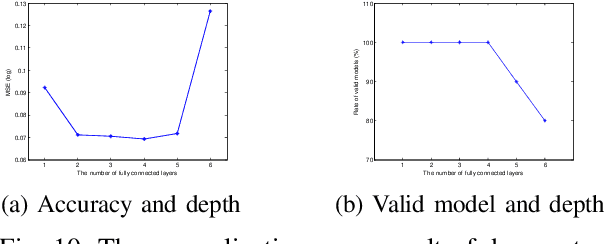
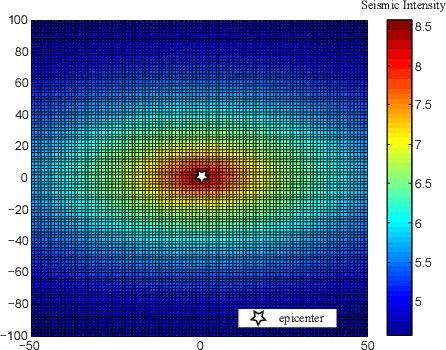
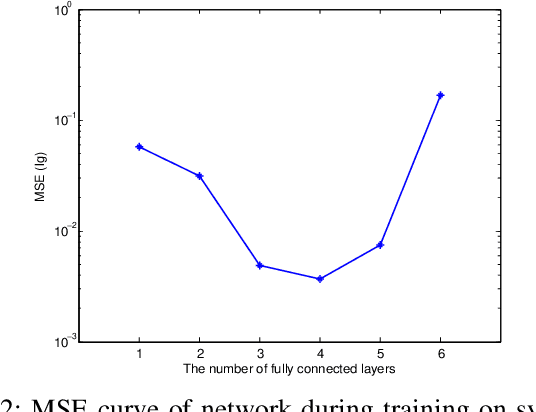
Deep learning is recognized to be capable of discovering deep features for representation learning and pattern recognition without requiring elegant feature engineering techniques by taking advantage of human ingenuity and prior knowledge. Thus it has triggered enormous research activities in machine learning and pattern recognition. One of the most important challenge of deep learning is to figure out relations between a feature and the depth of deep neural networks (deep nets for short) to reflect the necessity of depth. Our purpose is to quantify this feature-depth correspondence in feature extraction and generalization. We present the adaptivity of features to depths and vice-verse via showing a depth-parameter trade-off in extracting both single feature and composite features. Based on these results, we prove that implementing the classical empirical risk minimization on deep nets can achieve the optimal generalization performance for numerous learning tasks. Our theoretical results are verified by a series of numerical experiments including toy simulations and a real application of earthquake seismic intensity prediction.