 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Popularity of Micro-videos with Multimodal Variational Encoder-Decoder Framework
Paper and Code

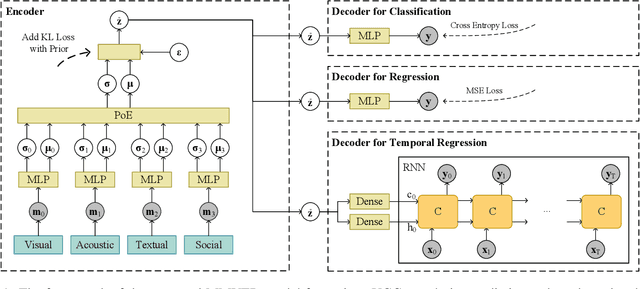
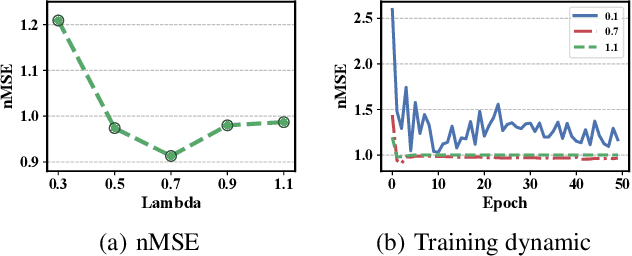

As an emerging type of user-generated content, micro-video drastically enriches people's entertainment experiences and social interactions. However, the popularity pattern of an individual micro-video still remains elusive among the researchers. One of the major challenges is that the potential popularity of a micro-video tends to fluctuate under the impact of various external factors, which makes it full of uncertainties. In addition, since micro-videos are mainly uploaded by individuals that lack professional techniques, multiple types of noise could exist that obscure useful information. In this paper, we propose a multimodal variational encoder-decoder (MMVED) framework for micro-video popularity prediction tasks. MMVED learns a stochastic Gaussian embedding of a micro-video that is informative to its popularity level while preserves the inherent uncertainties simultaneously. Moreover, through the optimization of a deep variational information bottleneck lower-bound (IBLBO), the learned hidden representation is shown to be maximally expressive about the popularity target while maximally compressive to the noise in micro-video features. Furthermore, the Bayesian product-of-experts principle is applied to the multimodal encoder, where the decision for information keeping or discarding is made comprehensively with all available modalities. Extensive experiments conducted on a public dataset and a dataset we collect from Xigua demonstrate the effectiveness of the proposed MMVED framework.